

当集群硬件资源有限,尤其SSD磁盘更紧俏的业务场景下,最大化集群的性能,如何让用户最关心的“热”数据分布到SSD磁盘对应的节点上,让用户关注程度弱的“冷”数据分散到普通磁盘对应节点上?也就是说“冷热”数据分离是本文讨论的内容。
提到冷热集群架构,通常我们关注的问题如下:
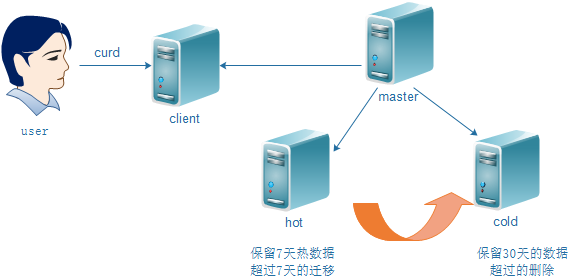
1、什么是冷热架构?
官方叫法:热暖架构——“Hot-Warm” Architecture。
通俗解读:热节点存放用户最关心的热数据;温节点或者冷节点存放用户不太关心或者关心优先级低的冷数据或者暖数据。
图片来源cnblog 毛台的博客
1.1 官方解读冷热架构
冷热架构是一项十分强大的功能,能够让您将 Elasticsearch 部署划分为“热”数据节点和“冷”数据节点。
将这两种类型的数据节点结合到一起后,您便能够有效地处理输入数据,并将其用于查询,同时还能在节省成本的前提下在较长时间内保留数据。
此架构对日志用例来说尤其大有帮助,因为在日志用例中,人们的大部分精力都会专注于近期的日志(例如最近两周),而较早的日志(由于合规性或者其他原因仍需要保留)则可以接受较慢的查询时间。
1.2 典型应用场景
一句话:在成本有限的前提下,让客户关注的实时数据和历史数据硬件隔离,最大化解决客户反应的响应时间慢的问题。
业务场景描述:
每日增量6TB日志数据,高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
2、最最核心的实现原理
借助 Elasticsearch的分片分配策略,确切的说是:
Shard allocation awareness
Index-level shard allocation filtering
3、7.X版本ES实践一把
第一:搭建一个两个节点的集群,划分热、热节点用。
节点层面设置节点类型。
热节点指定:
1node.attr.hotwarm_type: hot
暖节点或冷节点指定:
1node.attr.hotwarm_type: warm
第二:写入操作
方案一:索引层面指定路由。
1PUT /logs_2019-10-01
2{
3 "settings": {
4 "index.routing.allocation.require.hotwarm_type": "hot",
5 "number_of_replicas": 0
6 }
7}
8
9
10PUT /logs_2019-08-01
11{
12 "settings": {
13 "index.routing.allocation.require.hotwarm_type": "warm",
14 "number_of_replicas": 0
15 }
16}
方案二:通过模板指定索引的冷热存储。
1PUT _template/logs_2019-08-template
2{
3 "index_patterns": "logs_2019-08-*",
4 "settings": {
5 "index.number_of_replicas": "0",
6 "index.routing.allocation.require.hotwarm_type": "warm"
7 }
8}
9PUT _template/logs_2019-10-template
10{
11 "index_patterns": "logs_2019-10-*",
12 "settings": {
13 "index.number_of_replicas": "0",
14 "index.routing.allocation.require.hotwarm_type": "hot"
15 }
16}
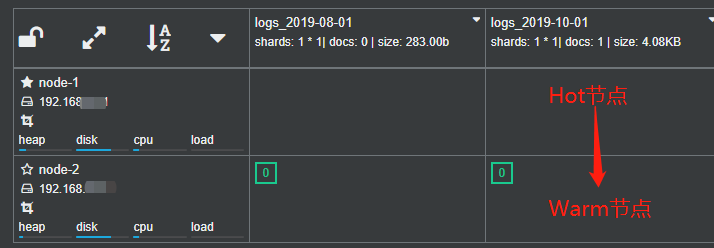
第三:效果图详见附件图。

可以看出,两个索引分不到不同的节点上。
第四:借助curator定期迁移数据
随着时间发展,当前数据会成为历史数据。
历史数据要自动切换到普通磁盘的节点存储,可以借助curator实现。
cuator的安装不再追溯,详细请参考官方文档。
1actions:
2 1:
3 action: allocation
4 description: >-
5 Apply shard allocation routing to 'require' 'tag=cold' for hot/cold node
6 setup for logstash- indices older than 3 days, based on index_creation
7 date
8 options:
9 key: hotwarm_type
10 value: warm
11 allocation_type: require
12 disable_action: false
13 filters:
14 - filtertype: pattern
15 kind: prefix
16 value: logs_
17 - filtertype: age
18 source: name
19 direction: older
20 timestring: "%Y-%m-%d"
21 unit: days
22 unit_count: 3
1C:Program Fileselasticsearch-curator>curator.exe --config .confcurator.yml .confaction.yml
22019-10-13 22:28:31,662 INFO Preparing Action ID: 1, "allocation"
32019-10-13 22:28:31,662 INFO Creating client object and testing connection
42019-10-13 22:28:31,668 INFO Instantiating client object
52019-10-13 22:28:31,668 INFO Testing client connectivity
62019-10-13 22:28:31,675 INFO Successfully created Elasticsearch client object with provided settings
72019-10-13 22:28:31,677 INFO Trying Action ID: 1, "allocation": Apply shard allocation routing to 'require' 'tag=cold' f....
82019-10-13 22:28:31,706 INFO Updating 2 selected indices: ['logs_2019-08-01', 'logs_2019-10-01']
92019-10-13 22:28:31,706 INFO Updating index setting {'index.routing.allocation.require.hotwarm_type': 'warm'}
102019-10-13 22:28:32,559 INFO Action ID: 1, "allocation" completed.
112019-10-13 22:28:32,560 INFO Job completed.
4、坑
1node.attr.hotwarm_type:
单纯搜索官网你是找不到的。
因为:node.attr.*,你可以指定type类型、各种结合业务场景你的需要指定的值。
包括:官方的按照磁盘大小设定。和咱们的冷热节点。
白话文:就是标定节点划分分类的一个属性类型值。
这个坑网友也有疑惑:node属性(tag)如何设置,查资料看到了好几种方法很混乱 – Elastic 中文社区,官方文档说的不是特别清楚。
5、线上使用场景
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777




