

今天的文章,主要向大家介绍 “不规则张量”。在许多情况下,数据不会均匀地分成可加载到张量中形状一致的数组。训练和处理文本就是这方面的经典案例。例如,如果查看使用 IMDB 数据集的文本分类教程,您会发现数据准备的一个主要部分就是将您的数据打造成标准大小。在这个例子中,每条评论的长度需要为 256 字。如果大于此长度,则将评论截短,如果小于此长度,则会使用 0 值来填充,直至达到所需长度。
不规则张量就是为解决这个问题而提出。它们是嵌套可变长度列表的 TensorFlow 张量,可以轻松储存和处理具有非均一形状的数据,例如:
举例来讲,在下面的语句中,每行的长度可能会有很大变化:
speech = tf.ragged.constant(
[[‘All’, ‘the’, ‘world’, ‘is’, ‘a’, ‘stage’],
[‘And’, ‘all’, ‘the’, ‘men’, ‘and’, ‘women’, ‘merely’, ‘players’],
[‘They’, ‘have’, ‘their’, ‘exits’, ‘and’, ‘their’, ‘entrances’]])
如果将这种语句打印出来,我们可以发现它是从一系列列表中创建的,并且每个列表的长度都是可变的:
您希望由正规张量支持的运算大多也可使用不规则张量,例如用于访问张量片的 Python 风格索引按预期运作:
>>print(speech[0])
tf.Tensor([‘All’, ‘the’, ‘world’, ‘is’, ‘a’, ‘stage’], shape=(6,), dtype=string)
tf.ragged 软件包还定义了大量特定于不规则张量的运算。例如,tf.ragged.map_flat_values 运算可以用于高效转换不规则张量中的单个值,同时保持其形状相同:
> print tf.ragged.map_flat_values(tf.strings.regex_replace,speech, pattern=”([aeiouAEIOU])”, rewrite=r”{1}”)
您可以在 详细了解受支持的运算。
不规则和稀疏
值得注意的是,不规则张量与稀疏张量不同,更像是形状不规则的密集张量。这里的关键区别在于,不规则张量会追踪每行的起止位置,而稀疏张量则需要追踪每个单独项目的坐标。您可以探索稀疏张量和不规则张量的深度连接,了解这一区别的影响。
连接稀疏张量相当于连接对应的密集张量,如下例所示(其中 Ø 表示缺失值):
但在连接不规则张量时,每个单独的行都会连接起来,形成一个具有组合长度的行:

使用不规则张量
在下面的示例中,我们使用不规则张量构造并组合单个词(一元语法)和词对(二元语法)的嵌入,以获得可变长度的短语字词列表。您也可以在不规则张量指南中自行尝试使用此代码。
import math
import tensorflow as tf
tf.enable_eager_execution()
# Set up the embeddingss
num_buckets = 1024
embedding_size = 16
embedding_table =
tf.Variable(
tf.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)),
name=”embedding_table”)
# Input tensor.
queries = tf.ragged.constant([
[‘Who’, ‘is’, ‘Dan’, ‘Smith’]
[‘Pause’],
[‘Will’, ‘it’, ‘rain’, ‘later’, ‘today’]])
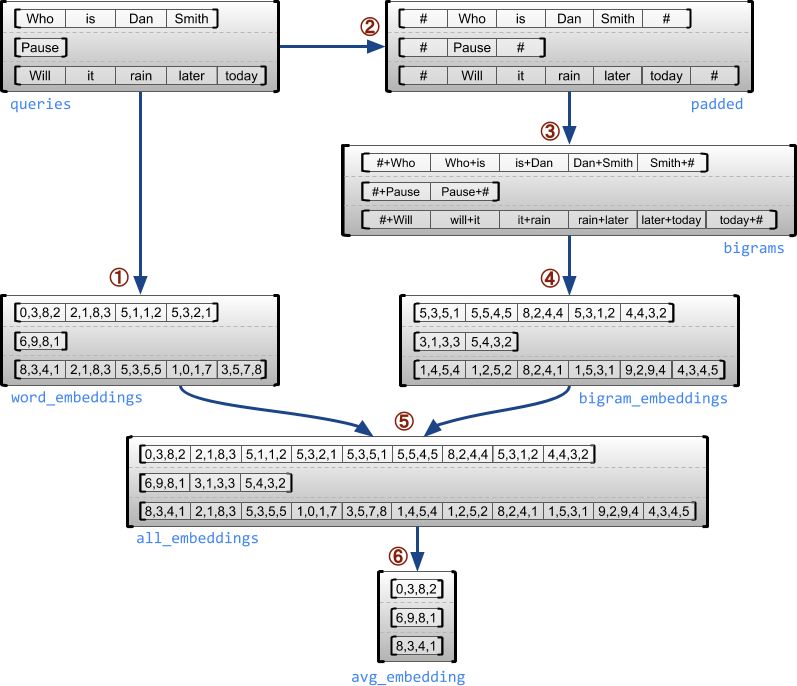
# Look up embedding for each word. map_flat_values applies an operation to each value in a RaggedTensor.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.ragged.map_flat_values(
tf.nn.embedding_lookup, embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows()), 1], ‘#’)
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams & look up embeddings.
bigrams = tf.string_join(
[padded[:, :-1], padded[:, 1:]], separator=’+’) # ③
bigram_buckets =
tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.ragged.map_flat_values(
tf.nn.embedding_lookup, embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings =
tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(word_embeddings)
print(bigram_embeddings)
print(all_embeddings)
print(avg_embedding)
下图中已有说明。请注意,这些数字仅作说明之用。关于嵌入中的真实值,请查看代码块底部的值输出。
结论
如您所见,不规则张量在许多情况下都非常有用,让您无需创建大小和排列相同的列表。当您存储和处理具有非均一形状的数据时,例如可变长度特征(如电影演员表)、多批可变长度顺序输入(例如句子)、分层数据结构(例如再次细分为节、段、句、词的文档)或结构化输入中的单个字段(如协议缓冲区),均可考虑使用不规则张量。对于这些用例,不规则张量要比填充的 tf.Tensor 更加有效,因为它省去了用在填充值上的时间和空间;而且也比使用 tf.SparseTensor 更加方便灵活,因为它支持种类广泛的运算,并且具有可变长度列表的正确语义。
目前,只有低级 TensorFlow API 支持不规则张量,但在未来几个月,我们将支持在整个 TensorFlow 堆栈中处理不规则张量,包括 Keras 层和 TFX。
这篇文章仅仅对不规则张量做了粗浅介绍,您可以在不规则张量指南中了解详情。如需有关不规则张量的更多文档,请访问 TensorFlow.org 上的tf.ragged 软件包文档
注:不规则张量指南 链接
tf.ragged 软件包文档 链接
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777




