10. 理解索引下推
看下如下SQL:
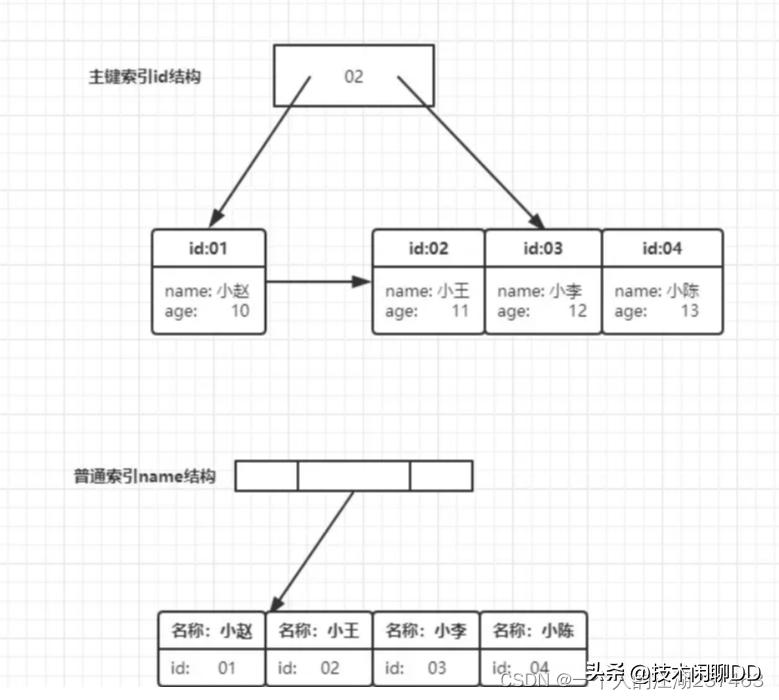
select * from employee where name like '小%' and age=28 and sex='0';其中,name和age为联合索引(idx_name_age)。
如果是Mysql5.6之前,在idx_name_age索引树,找出所有名字第一个字是“小”的人,拿到它们的主键id,然后回表找出数据行,再去对比年龄和性别等其他字段。如图:
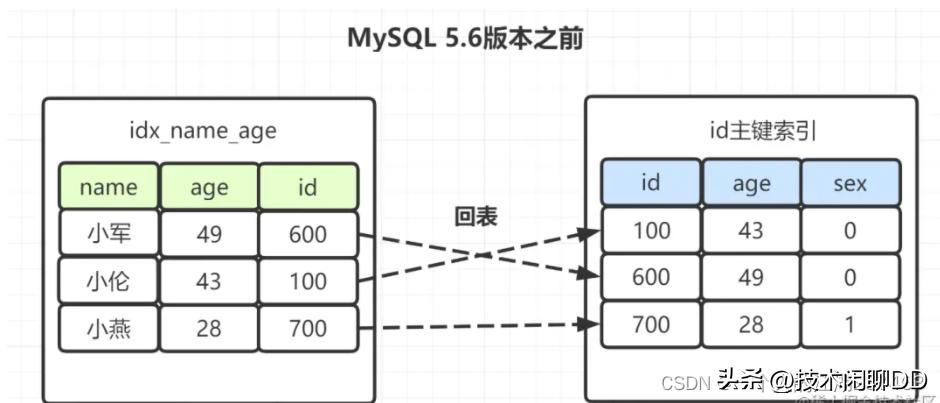
这时候我们会感觉奇怪,idx_name_age(name,age)是联合索引,为什么选出包含“小”字后,不再顺便看下年龄age再回表呢,所以在MySQL 5.6就引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
因此,MySQL5.6版本之后,选出包含“小”字后,顺表过滤age=28
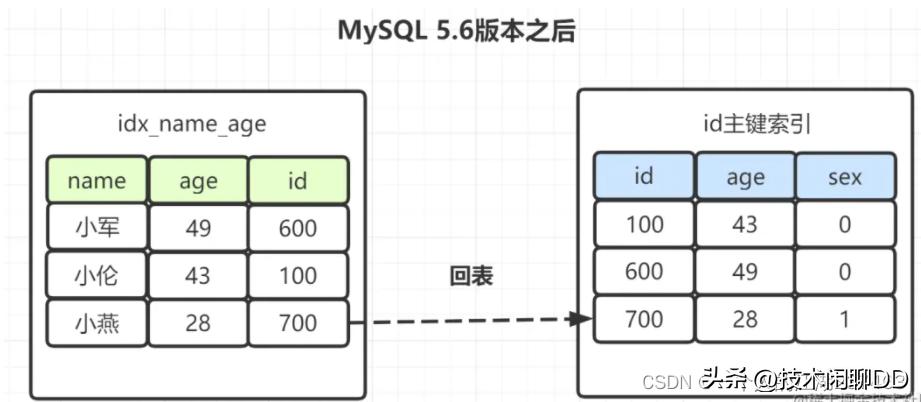
其实就一句话:在搜索引擎中提前判断对应的搜索条件是否满足,满足了再去回表,通过减少回表次数进而提高查询效率。
11. 大表如何添加索引
如果一张表数据量级是千万级别以上的,如何给这张表添加索引?
要注意一点:给表添加索引的时候,是会对表加锁的。如果不谨慎操作,有可能出现生产事故的。可以参考以下步骤:
创建一张和原表结构一样的空表,只是表名不一样;
create table tb_name_tmp like tb_name;把新建的空表非主键索引都删掉,因为这样在往新表导数据的时候效率会很快(因为除了必要的主键以外,不用再去建立其它索引数据了)
alter tb_name_tmp drop index index_name;从旧表往主表里导数据,如果数据太大,建议分批导入,只需确保无重复数据就行,因为导入数据太大,会很占用资源(内存,磁盘io, cpu等),可能会影响旧表在线上的业务。我是每批次100万条数据导入,基本上每次都是在 20s左右;
insert into tb_name_tmp select * from tb_name where id between start_id and end_id;数据导完后,再对新表进行添加索引;
create index index_name on tb_name_tmp(column_name);当大部分数据导入后,索引也建立好了,但是旧表数据量还是会因业务的增长而增长,这时候为了确保新旧表的数据一至性和平滑切换,建议写一个脚本,判断当旧表的数据行数与新表一致时,就切换。我是以 max(id)来判断的。
table tb_name to tb_name_tmp1;
table tb_name_tmp to tb_name;12. 如何知道语句是否走索引查询?
可以采用explain关键字查看SQL的执行计划,就可以知道是否命中索引。
当explain与SQL一起使用时,MySQL将显示来自优化器的有关语句执行计划的信息。
一般来说,我们需要重点关注type、rows、filtered、extra、key。
12.1 type
type表示连接类型,查看索引执行情况的一个重要指标。以下性能从好到坏依次:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
12.2 rows
该列表示MySQL估算要找到我们所需的记录,需要读取的行数。对于InnoDB表,此数字是估计值,并非一定是个准确值。
12.3 filtered
该列是一个百分比的值,表里符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
12.4 extra
该字段包含有关MySQL如何解析查询的其他信息,它一般会出现这几个值:
12.5 key
该列表示实际用到的索引。一般配合possible_keys列一起看。
13. Hash 索引和 B+树区别是什么?设计索引如何抉择?14. 索引有哪些优缺点?
优点:
缺点:
15. 聚簇索引与非聚簇索引的区别
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。它表示索引结构和数据一起存放的索引。非聚簇索引是索引结构和数据分开存放的索引。
分不同的引擎:
在MySQL的InnoDB存储引擎中, 聚簇索引与非聚簇索引最大的区别,在于叶节点是否存放一整行记录。聚簇索引叶子节点存储了一整行记录,而非聚簇索引叶子节点存储的是主键信息,因此,一般非聚簇索引还需要回表查询。
而在MyISM存储引擎中,它的主键索引,普通索引都是非聚簇索引,因为数据和索引是分开的,叶子节点都使用一个地址指向真正的表数据。
今天给大家就把索引这块的相关核心点说完了,希望能给大家在学习和面试中有一点帮助,也希望大家多多点赞支持!!
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777