一.缓存的产生与发展1.1 什么是缓存?
缓存(cache),原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器。Cache一词来源于1967年的一篇电子工程期刊论文,用于电脑工程领域。
1.2 缓存的发展?
问题:最开始的PC机处理器CPU没有Cache,CPU直接访问内存数据,访问数据的速度匹配不上CPU的处理速度。
手段:后来英特尔公司对CPU增加了对可选的Cache的支持,当CPU处理数据时,它会先到Cache中去寻找,如果数据因之前的操作已经读取而被暂存其中,就不需要再从随机存取存储器(Main memory)中读取数据,从而加快读取数据速度。
优化:在CPU内核增加L2 Cache(二级缓存),甚至三级缓存,超高速缓存等。
1.3 缓存概念的扩充
如今我们知道缓存的概念不仅仅限于在CPU和主内存之间,在硬盘与网络之间、在软件与硬件之间、在系统应用与数据库之间等也有某种意义上的Cache。
总之,凡是位于处理数据速度相差较大的两种介质之间,用于协调两者数据传输速度差异的结构,均可称之为Cache。
1.4 缓存在应用服务中的发展
随着网络发展及普及,用户量级增长,我们的应用服务器及数据库服务器同时需要处理大量的请求及数据计算,而我们的应用服务器资源有限、数据库同时可处理请求能力也有瓶颈,如何利用有限的资源承载更高的并发提高应用的吞吐能力呢?其中一个较为有效的方式就是引入缓存。即通过缓存快速访问需要数据并返回,减少系统交互,提高计算响应能力。
总之,尽可能将数据放在最近最直接最快速获取的地方,协调应用获取数据与存储数据返回之间速度的差异。
二.缓存的应用2.1 缓存的分类
在目前的应用服务框架中,根据应用服务于缓存之间的耦合程度,比较常见的分为local cache(本地缓存)和remote cache(分布式缓存/共享缓存)。
本地缓存
存在于应用中的,能够直接访问获取数据,无网络开销的存储介质。
优点:其存储位置与应用在同一上下文环境中或者在同一进程中,无需过多网络开销,访问速度非常快。
缺点:1)每个应用实例都要维护一套缓存数据,数据不共享;2)数据一致性问题,由于更新不及时,缓存中维护的数据可能不正确;3)无法进行大数据存储,数据无持久化随着应用重启而丢失。
应用场景:1)缓存的数据一般为静态不常变更的只读数据;2)短时间变更对业务影响不敏感的数据;
本地缓存的实现:
分布式共享缓存
缓存与应用分离,缓存本身即为一种应用,如常见的Redis、Memcached、美团的Cellar都属于共享缓存或者共享缓存的实现。
优点:1)数据共享,保证数据一致性,各节点通过统一的分布式缓存进行数据存取操作,保证了不同节点的应用进程的数据一致性问题;2)数据读写分离,高性能,高可用;3)支持大数据量存储,不受应用进程重启影响;
缺点:1)数据跨网络传输,性能低于本地缓存
应用场景:具体场景具体分析,一般适合数据结构简单、需要高性能读写且具备分布式共享的数据存储。
2.2 常见框架组件对缓存的应用2.2.1 MyBatis的缓存一级缓存
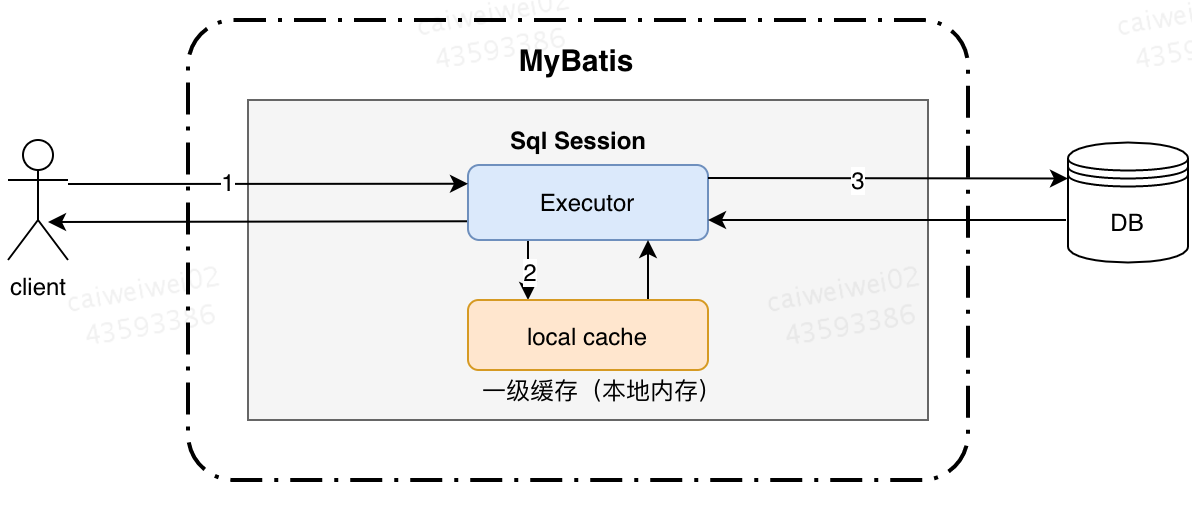
MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象会持有有一个新的Executor对象,Executor对象持有一个新的PerpetualCache(其内部包装了HashMap存储数据)对象也就是所要操作的Local Cache。当用户进行查询时MyBatis会在Local Cache进行查询,如果缓存命中的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,再将结果写入Local Cache,最后返回结果给用户。
二级缓存
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。与一级缓存的区别是缓存的有效范围从SqlSession内提升到Application内。

1.MyBatis的二级缓存作用域是SessionFactory,该缓存是以namespace为单位的(也就是一个Mapper.xml文件),不同namespace下操作互不影响。
2.MyBatis的二级缓存相对于一级缓存来说,实现了SqlSession之间缓存数据的共享。
3.MyBatis的二级缓存使用要求比较严格,在多表查询或分布式系统中有多表查询时容易出现脏数据,此时需要使用集中式缓存实现,如使用redis替代。
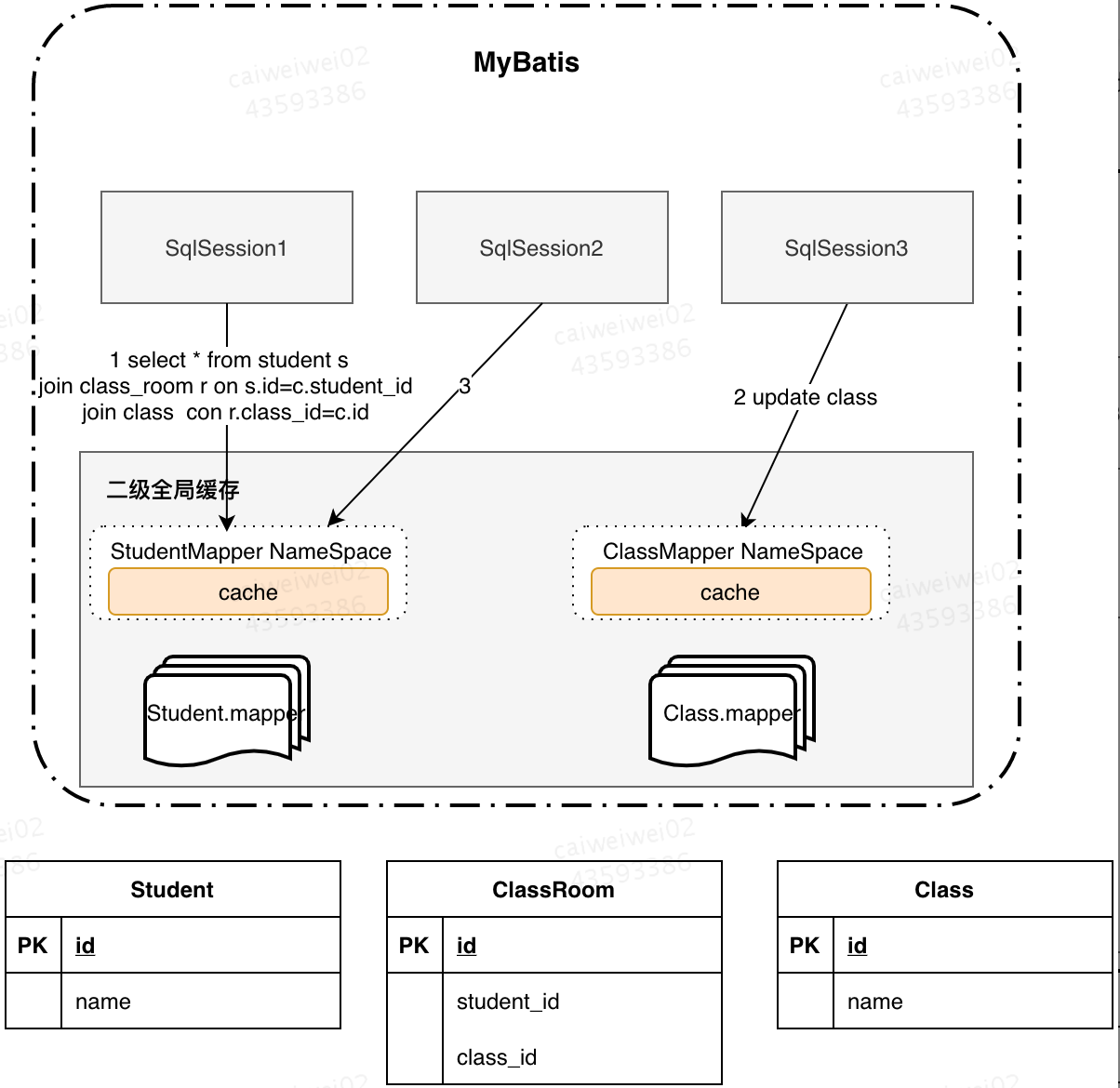
1.SQLSession1通过联表查询学生所在班级名称(name),查询过后此时二级缓存生效,保存在StudentMapper的namespace下的cache中;
2.SqlSession2更新班级名称(name),update class操作不属于StudentMapper的namespace,所以StudentMapper下的cache没有感应到变化,没有刷新缓存。
3.SqlSession3执行同1中的查询操作,查询出来的数据还是StudentMapper的namespace下的cache中缓存的数据。
为了解决以上问题,可以使用Cache ref,让ClassMapper引用StudenMapper命名空间,这样两个映射文件对应的SQL操作都使用的是同一块缓存了。不过这样做的后果是,缓存的粒度变粗了,多个Mapper namespace下的所有操作都会对缓存使用造成影响。
2.2.2 Spring缓存
自Spring3.1开始,Spring就自带了对缓存的支持,其本质上不是一个具体的缓存实现方案,而是一个对缓存使用的抽象。我们可以直接使用Spring缓存技术将某些数据放入本机的缓存中。
Spring Cache的关键原理就是Spring AOP,通过Spring AOP实现了在方法调用前、调用后获取方法的入参和返回值,进而实现了缓存的逻辑。
2.2.3 Redis共享缓存
对于Redis大家已经耳熟能详,也在业务应用中经常使用,Redis因其高性能、丰富的数据结构等特性在互联网中有着广泛应用:应用最多的领域是缓存,同时也是分布式锁常用的实现方式,除此之外Redis还可以应用于实现消息队列、排行榜、网站统计等。
关于redis支持的数据结构、数据淘汰策略、分布式锁的实现、持久化方式等这里不过多介绍了,大家自行搜索相关资料即可。这里讨论几个问题
1.Redis为什么被设计为单线程?
2.Redis为什么那么快?
3.什么时候用Redis?
2.3 缓存带来的问题2.3.1 本地缓存
比较明显的是在分布式系统中各服务实例中数据一致性问题,由于更新不及时,缓存中维护的数据可能不正确,进而对业务产生影响。
解决方案:
采用定时刷新+监听刷新结合的方式,在定时刷新的基础上增加监听刷新,当数据库数据产生变化时各服务实例监听到变化信号时刷新本地缓存。
2.3.2 分布式共享缓存
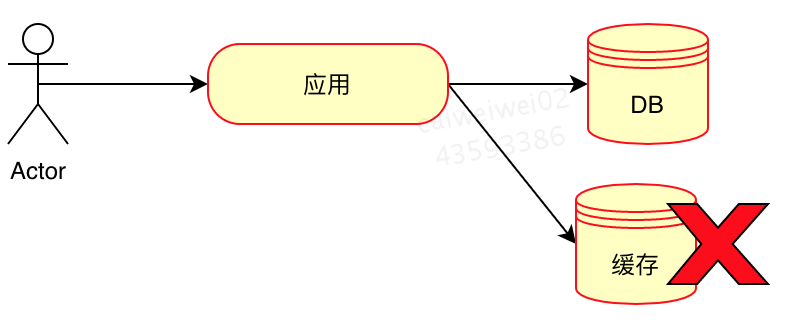
一致性问题是分布式常见问题,数据库和缓存双写,就必然会存在不一致的问题。
解决方案:
首先,对数据一致性要求进行分析,如果对数据有强一致性要求,则不能放缓存。此外,其它对实时强一致要求不高的数据,我们只能保证最终一致性,因为我们所做的方案其实从根本上来说,只能降低不一致发生的概率,无法完全避免。
其次,采取正确更新策略,因为可能存在删除缓存失败的问题,则需要提供一个补偿措施,例如利用消息队列。
概念:所谓缓存穿透就是说在缓存中不存在,然后直接在数据库中查询的现象。
引发场景:一般来说,缓存穿透的场景发生在故意攻击的场景下。比如说,大量并发查询的数据都不在缓存中,缓存失效,全部流量都打在了数据库中,如果某一时刻流量过大,则会导致数据库崩溃。

解决方案:
1)采用异步更新策略,无论key是否取到值,都直接返回。对value值维护一个缓存失效时间,缓存如果过期,起一个异步线程去读数据库,更新缓存;另外需要做缓存预热(项目启动前,先加载缓存)操作。
2)提供一个能迅速判断请求是否有效的拦截机制。比如,利用布隆过滤器,内部维护一系列合法有效的key,迅速判断出请求所携带的Key是否合法有效,如果不合法,则直接返回。
概念:所谓缓存雪崩就是在某一个时刻,缓存集大量失效。所有流量直接打到数据库上,对数据库造成巨大压力。
引发场景:缓存设置失效时间一样,在同一时间失效,同时有大量请求访问,如秒杀。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。设置热点数据永远不过期。双key缓存策略。设置两个缓存,缓存A和缓存B。缓存A设置失效时间,缓存B不设失效时间,如果查询A无数据则查询B返回,同时起一个异步线程同时更新AB。三.总结
1.通过缓存的基本介绍,认识常用的本地缓存和共享缓存不同的特点及使用场景。
本地缓存和共享缓存在某种情况下都存在数据与数据库数据不一致问题,如何解决需要考虑清楚,另外目前来看本地缓存在分布式系统中的应用解决不一致问题需要有较为复杂的方案才能解决。
2.在使用缓存之前需要思考的方向
3.慎用本地缓存,尤其在分布式系统中对数据实时性和敏感性要求较高的数据,它们带来的问题可能比收益要多。
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777