

Louvain算法是目前单细胞分析中最常用的聚类算法[1],Seurat/Scanpy/RaceID等单细胞分析工具都默认louvain算法。6天前HumanCell Atlas(HCA)团队发表在Nature Method上的单细胞分析流程中[2],默认的聚类算法是scran包的方法:细胞间权重基于排序计算(rank-based),聚类算法用Walktrap。这跟杰卡德距离+Louvain算法的方法截然不同。
聚类算法孰优孰劣,此前已经有人做过比较。2016年Scientific Reports上有一篇文章比较了igraph包里的8种聚类算法,其中包括了Louvain和Walktrap[3]。测试结果的准确率Louvain和Walktrap相近。但是,当节点数(细胞数)大于6000时,Louvain的表现要优于Walktrap。
总结评测结果,Louvain算法表现是最好的。但仍有不少文章选择其他聚类算法,因为louvain算法有以下几个缺点:
社区划分的精度有局限性[4];
分组内细胞分布密度的大小会影响亚群的鉴定[2];
被鉴定为同一个分群的细胞群内,存在两个没有连线的小分群[5]。
Leiden算法主要针对上述的第3个缺点,对louvain算法进行优化[5]。
Leiden算法的命名来源于荷兰莱顿大学(Leiden University)。该算法由莱顿大学的三位研究员开发,结果于今年3月份发表在Scientific Reports上。

想了解louvain算法的聚类过程,可以回顾往期文章:
总结Leiden算法优化louvain的两个要点:
比louvain算法运行更快。
针对louvain聚类结果中出现一些分群内部存在断链的现象(连线没有把所有细胞串起来,存在明显亚群)进行优化,分群更加合理,可能得到更多亚群。
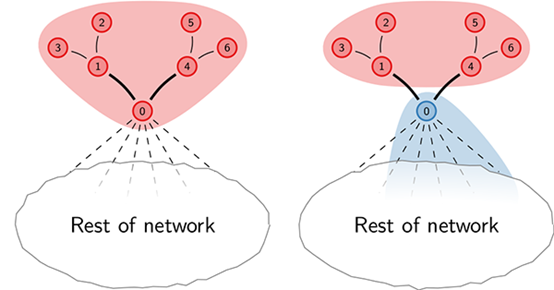
图解leiden算法的操作过程
我们可以把聚类过程当作体育课的一场游戏。
学生是细胞,在操场上站队(聚类)。
模块度是体育老师,检查学生站队是否合理。
连线(细胞间权重)表示学生之间有一定的关系,比如同班同学,身高一致等。
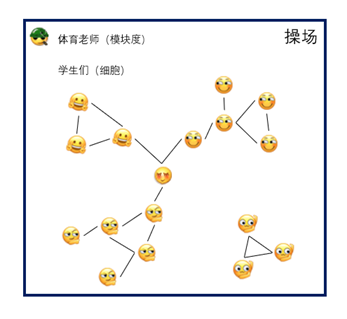
经过学生的一阵骚动(初始划分聚类)之后,初始的队伍出来了,分成的三个队伍:
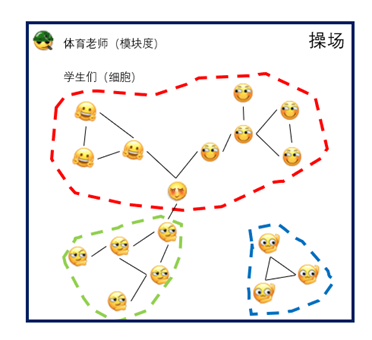
这时体育老师出来,看了看整体队形(模块度给聚类结果打分),感觉还不行(模块度分数偏低),需要调整分组站队。
Leiden和louvain算法的调整策略不同(leiden优化的要点一):
Louvain:让每个同学去另外两个队伍,每次换队伍都让体育老师评价一下;
Leiden:只让每个同学去有连线的其他队伍,节省时间。
当害羞同学
从红队调整到绿队时,体育老师发现队形变好看了(模块度打分提高了)。因为红队身高整体比绿队高,害羞同学
比较矮,适合绿队。害羞同学刚开始站在红队,是因为她跟红队是同班同学。

但害羞同学
离开红队之后,问题就来了。红队内部出现左右两个没有连线的小队:耶小队
和奸笑小队
。Louvain算法没有检测这种内部断链的现象。尽管红队都是同班同学,但内部还是有身高的差异,耶小队
比奸笑小队
普遍矮小。之前不高不矮的害羞同学
在的时候,还能起到内部过渡的作用。当害羞同学
离开之后,红队内部出现两极化。

幸亏体育老师提前备课,看了leiden算法,及时将红队分开。(leiden优化要点二)
下课铃声响起,体育老师手握Leiden书,看着同学们完美的队形,露出了满意的微笑。
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777




