

©作者 |王利民
学校 |南京大学
研究方向 |视频理解
本文介绍我们最近被 NeurIPS 2022 接收的时序动作检测工作 PointTAD: Multi-Label Temporal Action Detection with Learnable Query Points。PointTAD 基于一组稀疏时序点(query points)来形成更加精细的动作时序表征,解决多类别时序动作检测中并发动作定位和复杂动作建模两大难题。
配合稀疏点设计,我们提出了基于时序点表示的有效训练策略和多尺度动作解码结构,大大增强了我们在较复杂的多类别视频中的动作检测能力。PointTAD 只基于 RGB 输入,支持端到端训练和测试、易于部署,在 MultiTHUMOS 和 Charades 这两个多类别视频数据集上获得了 SOTA 的 detection-mAP。
这篇工作由南京大学媒体计算组(MCG)和腾讯 PCG 联合完成。
论文标题:
PointTAD: Multi-Label Temporal Action Detection with Learnable Query Points
论文链接:
代码链接:

研究动机
时序动作检测(Temporal Action Detection, TAD)旨在对一段未经剪辑的视频检测其中人类动作的开始、结束时间和动作类别。经典的时序动作检测面向的是一个较为理想的视频场景。
在常用的 TAD 数据集(THUMOS,ActivityNet,HACS)中,大部分视频只被标注了同一个类别的动作:85% 的 THUMOS 视频只标注了同一个类别的动作。不仅如此,这些动作标注之间也基本不存在时序上的重合。因此,主流的经典 TAD 工作常常将任务简化成由时序候选框生成和视频分类组成的两阶段问题。
然而在现实场景中的视频里,不同类别的动作往往会同时发生。因此,我们将研究重心转移到更加复杂的多类别时序动作检测(Multi-label Temporal Action Detection, Multi-label TAD),在包含多种类别的动作标注的视频中检测出所有动作。
过往的 Multi-label TAD 方法采用密集预测的方法来解决这个问题:在输入视频的每一帧预测一个类别向量进行多类别分类。密集预测无法生成由一对开始-结束时间点组成的动作预测,容易形成不完整的预测框,因此定位效果较弱。类似图片实例分割,我们认为很有必要将 Multi-label TAD 从一个帧级别的分割问题重新定义为一个实例检测问题,其输出除了包括动作标签外,还应该包括由开始-结束时间戳表示的确切时序位置。
虽然经典 TAD 方法是从实例检测的角度来解决动作的时序定位,但直接套用经典 TAD 框架并不能很好的解决 Multi-label TAD 中存在的并发动作精细定位和复杂动作建模这两大挑战。经典的 TAD 框架依赖于动作 segment,并采用均匀采样从 segment 上形成动作表征。这样的策略无法灵活的同时关注动作内部重要的语义帧和动作边缘具有区分性的边界帧。
如图 1 所示,在检测动作 “Jump” 的时候,基于 segment 的动作检测方法往往会产生两类错误预测:S1 虽然正确的预测了动作类,但因为只捕捉到了动作的语义关键帧而形成了不完整的动作框;S2 较好的预测了动作的边界,但由于粗糙的动作表征导致了分类错误。因此,我们需要一种更加精细的时序动作检测框架来同时建模动作内部的语义关键帧和动作边界帧。

▲ 图1. 基于segment的时序动作检测模型在Multi-label TAD任务上的预测和错误案例。
基于上述的问题,我们基于先进的 query-based 框架提出了一种基于稀疏点表示的时序动作检测框架。相比于在 segment 上均匀采样,稀疏的时序点可以较为灵活的为不同的动作学到较为重要的帧的位置,通过提取点对应的特征即可获得一个更加精细的特征表示。
为约束时序点的学习,我们 follow RepPoints [1],用回归损失函数直接规约点的位置分布。给定 groundtruth 动作的位置和类别,时序点可以自适应的定位到动作的边界帧和动作内部的语义关键帧。
因此,有较大重叠的动作可以通过不同的时序点位置获得不同具有区分性的特征。配合稀疏点表示,我们提出多尺度交互模块(Multi-level Interactive Module)来增加并发、复杂动作解码能力。
多尺度交互模块在 point-level 利用基于动作特征向量的可变形算子在邻域连续帧上进行时序建模,为每个时序点生成局部点特征;在动作 instance-level 采用基于动作特征向量的 frame-wise 和 channel-wise 的动态一维卷积,沿着同一动作预测中的时序关键帧和特征通道并行地完成 mixing 操作。具体细节参见方法小节和原文。

方法介绍
PointTAD 采用 query-based 时序动作检测框架,包含两个部分:backbone network 和 action decoder,模型支持端到端训练和测试,结构图如图 2。类似 AdaMixer [2] 等 query-based 检测器,我们将动作 query 解耦为一组 query points 和一个 query vector,其中 query points 主要表示动作的时序位置,query vector表征动作特征。
在每一个解码层,依据 query point 特征通过多尺度交互模块更新 query vector,更新后的 query vector 再预测偏移量更新 query point,每一层输出的 query points 和 query vector 都作为输入传递到下一层。

▲ 图2. PointTAD模型示意图
2.1 基于可学习时序点的稀疏表示
由于视频内容在时序上存在冗余、且在不同时序位置的冗余程度不一致,因此基于 segment 生成的动作表征(用一对开始-结束时间点表示一个动作)很难在定位动作边界位置的同时从内容中准确提取关键内容。我们提出了一组可学习的 query points 集合来更加灵活地采样动作表征:同时采样动作的边界帧和语义关键帧。我们主要介绍 query points 的迭代过程和学习策略。
时序点的迭代更新:在训练过程中,query points 被初始化在输入视频的中点,而后在每个解码层被对应的 query vector 所更新。在第 层解码层,query vector 为 个 query points 预测偏移量,偏移量被参数 缩放后更新点的位置:。缩放参数 度量了当前 query points 的时序分布直径,在动作较短时缩短更新步长,帮助较短动作的精细调整。
基于伪框的学习策略:由于 query points 的分布灵活,因此需要可靠的训练策略约束这些点学习动作的边界帧。我们设计了一种基于 pseudo segments(伪框)的训练策略,将每层解码层更新后的 query points 转化为 pseudo segments 加入样本标签分配和回归损失函数计算。将 query points 映射为 pseudo segments 的函数记为 。我们探究两种不同的转换函数:Min-max()和 Partial Min-max()。
1. Min-max 取点集 中的时序位置最小值和时序位置最大值作为 pseudo segment 的开始和结束帧:。在 Min-max 的训练策略下,query points 只会学习到动作内部的关键帧,而对动作上下文的建模较少。
2. Partial Min-max 首先从点集 中取子集 ,而后在 中取时序最小最大位置形成伪框:。Partial Min-max 在 Min-max 的基础上允许 中的点不受回归损失函数约束,可以在全局范围结合动作的上下文特征。
我们在消融实验对比了两种转换函数的性能,并选择 Partial Min-max 作为默认转换函数。
2.2 多尺度交互模块
除了动作的 segment 表示带来的问题,之前的时序动作检测器在对采样帧的解码过程中也缺乏对帧之间多尺度语义信息的考察。配合稀疏点表示,我们在动作解码器设计了多尺度交互模块,从点层次结合局部时序信息生成 query point 特征、从实例层次对候选框内的时序点的关系建模。
点层次和实例层次的可变形参数和动态卷积参数都由动作特征(query vector)通过线性变换得到,使得每个动作预测对其对应的时序点都有各自的变换,形成具有区分性的特征。模块的示意图如图 3。

▲ 图3. 多尺度交互模块(Multi-level Interactive Module)示意图
点层次的局部可变形算子:在 point-level,我们利用局部可变形卷积为每个时序点建模邻域的时序结构。以每个 query point 为中心点,我们基于 query vector 预测 4 个偏移量和对应的权重,形成 4 个 sub-point。用双线性插值采样 sub-point 之后,对权重归一化并加权相加 sub-point 特征,得到中心 query point 的特征。
实例层次的自适应动态卷积:在 instance-level,我们不仅对每个 query point 的特征进行通道建模,也对描述同一个动作候选的所有 query points 之间的特征进行建模。我们采用 Sparse R-CNN [3],AdaMixer [2]中的动态一维卷积沿着通道和关键帧进行 Mixing(混合)。
区别于之前的检测器,我们发现顺序卷积对检测性能有较大的损害(见消融实验),因此采用并行结构对通道和帧进行 mixing (Parallel Mixing)。对通道维度我们采用 bottle-neck 的两层动态卷积,对时序维度我们采用一层动态卷积。Mixing 后的特征沿着通道拼合,通过 linear 变换到 query vector 的维度,通过残差结构更新 query vector。
2.3 训练与测试
损失函数:类似其他 query-based 时序动作检测框架 RTD-Net [4],我们用 hungarian matcher 来进行正负样本分配,根据预测和 gt 的匹配结计算损失函数。

除此之外,为了保持与过往Multi-label TAD 工作一致,我们基于预测结果计算segmentation-mAP,并额外密集预测 per-frame的类别向量来辅助 instance prediction结果。因此,在分类损失函数中我们加入一项per-frame loss,在dense prediction结果和 dense groundtruth 之间计算cross-entropy loss来帮助学习 per-frame的类别向量,得到最终的损失函数表示。
测试:PointTAD 采用线性层从 query vector 中预测动作向量,用 query points 生成的伪框作为动作定位结果。对于 detection-mAP,我们直接用 instance 预测结果计算。对于 segment-mAP,我们将 instance 预测和 dense per-frame 类别向量 融合得到密集预测结果 参与计算:

实验结果与可视化
3.1 实验结果
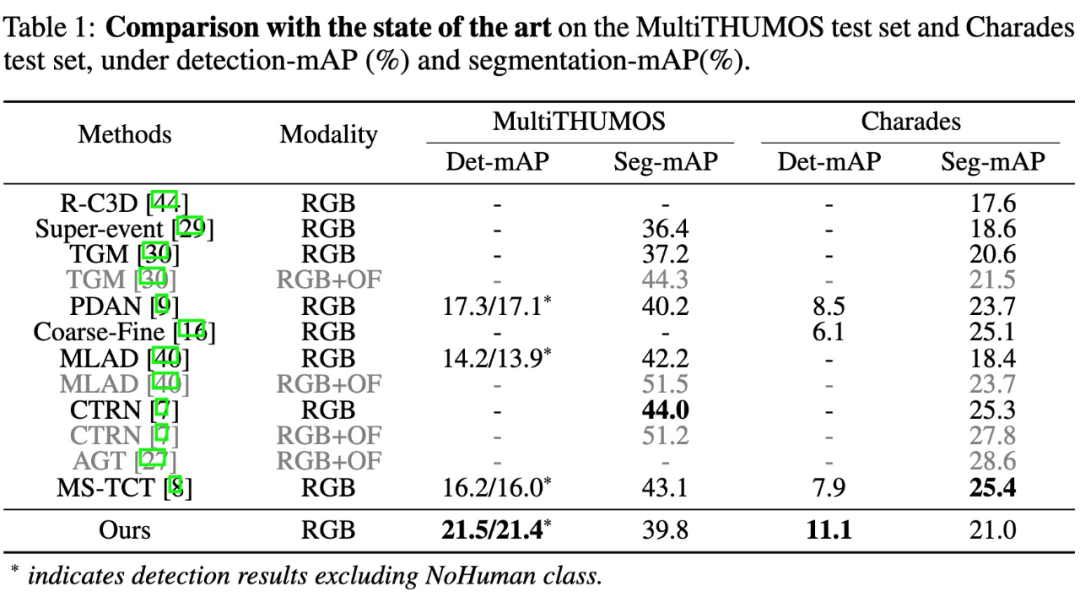
我们在 MultiTHUMOS 和 Charades 上进行实验,计算了 detection-mAP 和 Segmentation-mAP。
可以看到,PointTAD 在更能度量动作检测性能的 detection-mAP 上远远超过之前的 Multi-label TAD 方法,在依赖于密集预测的 segmentation-mAP 上也取得了 comparable 的结果。
3.2 消融实验
我们在 MultiTHUMOS 上进行多个消融实验,验证各模块的效果。在此讨论几个比较有意思的实验。

▲ 表(a),(f)来自正文 Table2,表(S7a)来自附录 Table7
3.3 结果可视化
我们可视化了单个动作预测中每层的 query point 位置,可以看到 local query points 可以很快的定位到动作位置,并进一步精细回归动作边界,global points 分布在全局范围结合上下文信息。

▲ 单个动作预测中每层的 query points 位置可视化
我们还可视化了多类别场景下的 query points 对不同类别的并发动作的检测,并展示每个 query point 所对应的关键帧。
可以看到对于重叠程度较大的动作 Fall,JavelinThrow(掷标枪)和 Run,我们的动作预测对应了不同的 query points,并且在类似的 background 下,query points 分别为 fall 动作的预测选中了人物摔倒的几帧,为掷标枪提取了描绘投掷动作的图片帧,为 Run 选中人物奔跑的帧而避开了投掷帧。由此可以看出,query point 确实可以学到语义关键帧,同时保持较好的定位效果。

▲ 多类别场景下的基于 query point 的动作预测可视化

总结
我们提出了基于稀疏点表示、端到端的 query-based 时序动作检测器 PointTAD。通过引入灵活的时序点/关键帧表示,我们可以同时关注动作的边界帧和语义关键帧,为复杂的多类别时序动作检测提供更加精细的动作表征。我们希望 PointTAD 对于 query points 的探究可以为时序动作检测领域对于精细动作表征的研究提供一个新的思路。
参考文献
[1] Yang, Z., Liu, S., Hu, H., Wang, L., & Lin, S. (2019). Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9657-9666).
[2] abGao, Z., Wang, L., Han, B., & Guo, S. (2022). AdaMixer: A Fast-Converging Query-Based Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5364-5373).
[3] Sun, P., Zhang, R., Jiang, Y., Kong, T., Xu, C., Zhan, W., … & Luo, P. (2021). Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 14454-14463).
[4] Tan, J., Tang, J., Wang, L., & Wu, G. (2021). Relaxed transformer decoders for direct action proposal generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 13526-13535).[5]Liu, X., Bai, S., & Bai, X. (2022). An Empirical Study of End-to-End Temporal Action Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20010-20019).
[6]Yang, M., Chen, G., Zheng, Y. D., Lu, T., & Wang, L. (2022). BasicTAD: an Astounding RGB-Only Baseline for Temporal Action Detection. arXiv preprint arXiv:2205.02717.
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777



