一个是全球领先的科技公司,一个是中国数据库基础学术研究的摇篮,近日,中国人民大学-腾讯协同创新实验室正式举行揭牌仪式。据了解,双方已聚焦在数据库基础研究领域进行了多年的前沿产学研合作,以及数据库人才合作培养计划,在推进数据库安全可控的同时面向未来大规模多场景数字化时代进行前沿创新研究储备,其中实验室输出的包括“全时态数据库系统”等多项成果相继被VLDB等国际顶会收录,同时申请获得了多项国家技术专利。

在本次实验室揭牌亮相的同时,腾讯与中国人民大学研究团队还开源公布了一项最新合作研究成果——3TS腾讯事务处理技术验证系统。

Tencent Transaction ProcessingTestbed System(简称3TS),是腾讯公司自研金融级分布式数据库TDSQL团队与中国人民大学数据工程与知识工程教育部重点实验室,联合研制的面向数据库事务处理的验证系统。该系统旨在通过设计和构建事务(包括分布式事务)处理统一框架,并通过框架提供的访问接口,方便使用者快速构建新的并发控制算法;通过验证系统提供的测试床,可以方便用户根据应用场景的需要,对目前主流的并发控制算法在相同的测试环境下进行公平的性能比较,选择一种最佳的并发控制算法。目前,验证系统已集成13种主流的并发控制算法,提供了TPC-C、Sysbench、YCSB等常见基准测试。3TS还进一步提供了一致性级别的测试基准,针对现阶段分布式数据库系统的井喷式发展而造成的系统选择难问题,提供一致性级别判别与性能测试比较。
3TS系统旨在深度探索数据库事务处理相关理论与实现技术,其核心理念是:开放、深度、进化。开放,秉承开源之心,共享知识、共享技术;深度,践行系统化钻研之精神,对于事务处理技术的本质问题进行研究,不破楼兰终不还;进化,路漫漫其修远兮,吾将上下而求索,不断前行,不断推进。
1、3TS 整体架构
作为一个事务处理技术相关的框架,3TS致力于探索的本质问题主要包括:
在代码层面,如上的每一类研究问题,都有对应的子系统。如首期开源的包括3TS-DA子系统混合3TS-Deneva子系统。
2、3TS-DA,数据异常子系统
3TS-DA数据异常子系统,位于src/3ts/da路径下,其项目结构如下图所示:

3TS-DA子系统当前功能:
3、3TS-Deneva,并发算法框架
Devena[1]是MIT开源的一个分布式内存数据库并发访问控制算法的评估框架,原始代码位于。它可以在受控环境下研究并发控制协议的性能特性。该框架提供了Maat、OCC、TO、Locking(No Wait、 Wait Die)、Calvin等主流算法。3TS-Deneva是腾讯在Deneva基础上对原有系统的改进,包括多个层面。其中在算法层面,增加了更多的并发访问控制算法,包括:可串行化、冲突可串行化、SSI、WSI、BOCC、FOCC、Sundial、Silo等。
3.1 基础架构
Devena使用了自定义的引擎以及其它一些设置,可以在这个平台上部署和实现不同的并发控制协议,以进行一个尽量公平的评估。该系统的架构,如图1所示,主要包括两大模块:
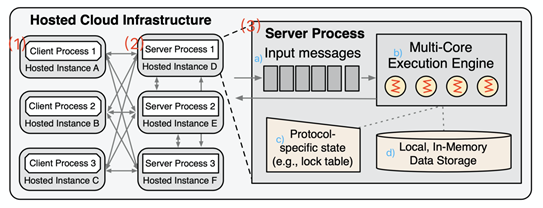
图1 Deneva系统架构图
在3TS中,对Deneva进行改进。改进后的代码位于contrib/deneva路径下,其内部项目结构如图2所示:
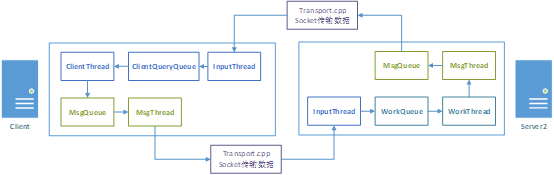
图2 Deneva实现框架图
3.2事务执行流程
在Deneva中,如图3所示,一个事务的执行流程为:
1)客户端首先发起一个事务请求(由多个操作组成),并将事务放到ClientQueryQueue中。ClientThread会从队列中取出事务请求存入消息队列MsgQueue。之后,消息发送线程会从MsgQueue中取出某一事务的操作集合,封装为一个Request,发送到某一服务端(通过第一个操作所访问的数据确定),作为这个事务的协调节点;
2)Request到达服务器后,服务器先对请求进行解析,并把这一事务的所有操作作为一个元素,放到工作队列(WorkQueue)中。工作队列中放置的有来自客户端的新事务和已经开始执行的事务的远程操作,后者在队列中比前者优先级更高。工作线程池中的线程轮询工作队列并处理事务中的操作。当某一工作线程处理当前事务的操作时,其首先对事务进行初始化,然后按顺序执行读写操作,并最终提交或者回滚;
3)当协调节点完成某一事务的操作后,他会将事务执行结果放入消息队列,然后由消息发送线程通知客户端当前事务的执行结果。
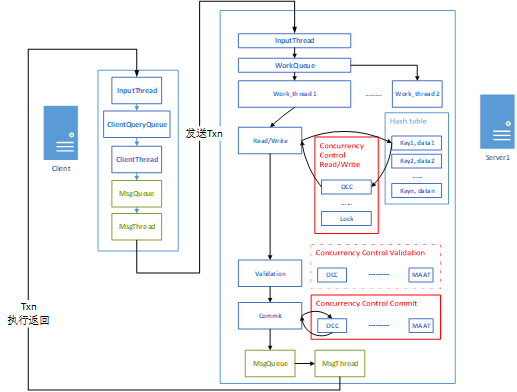
图3 Deneva事务执行流程图
4、分布式事务概述
文献[15]对分布式事务定义为:
A distributed transaction is a database transactionin which two or more network hosts are involved. Usually, hosts providetransactional resources, while the transaction manager is responsible forcreating and managing a global transaction that encompasses all operationsagainst such resources. Distributed transactions, as any other transactions,must have all four ACID (atomicity, consistency, isolation, durability)properties, where atomicity guarantees all-or-nothing outcomes for the unit ofwork (operations bundle).
分布式事务以分布式系统为物理基础,实现了事务处理的语义要求,即也要在分布式系统上满足ACID特性。所以分布式数据库的分布式事务处理,同样要遵循单机数据库系统下的事务相关理论,确保每个事务符合ACID的要求,采用分布式的并发访问控制技术来处理分布式系统下的数据异常现象,实现分布式的事务ACID特性。
分布式事务处理机制的基本技术,以单机数据库系统中的事务处理技术为基础,但也有些不同,诸如如何处理分布式数据异常、如何做到分布式架构下的可串行化,如何做到跨节点的原子提交,如何做好存在网络分区或有较高延时下事务的响应等。
3TS框架,是一个分布式环境,这些内容,都将在3TS中得到实现和验证。
5、3TS提供的并发访问控制算法
3TS中目前集成了十三种并发few你控制算法,主要包括:
(1)两阶段封锁协议(2PL:No-Wait,Wait-Die)
(2)时间戳排序协议(T/O)
(3)多版本并发控制协议(MVCC)
(4)乐观并发控制协议(OCC、FOCC、BOCC)
(5)优化的乐观并发控制协议(MaaT、Sundial、Silo)
(6)确定性并发控制协议(Calvin)
(7)基于快照隔离的并发控制协议(SSI、WSI)
下面依次对这些并发控制协议进行简要介绍:
5.1 两阶段封锁协议(2PL)
两阶段封锁协议(Two-phase Locking, 2PL)是目前最广泛应用的并发控制协议。2PL依靠读写操作发生时获取共享锁或排他锁的方式,来对事务间的冲突操作进行同步。根据Bernstein和Goodman的描述[2],2PL对锁的获取有如下两条规则:1)同一个数据项上不能同时存在两个互相冲突的锁;2)一个事务在释放了任意一个锁之后,不能再获取锁。第二条规则规定了事务中的锁操作分为了两个阶段:生长阶段(growing phase)和衰减阶段(shrinking phase)。在生长阶段中,事务将为其需要访问的所有记录获取锁。读取操作获取共享锁,写入操作获取互斥锁。共享锁是不冲突的,互斥锁与共享锁或其他互斥锁冲突。一旦某一事务释放了其中任意一个锁,事务便进入2PL的第二阶段,称为衰减阶段。进入此阶段后,事务就不允许获取新的锁。
3TS实现了直到事务提交或终止后才释放锁的严格2PL(Strict 2PL)协议。根据避免死锁方法的不同,3TS中实现的2PL包括两种:2PL(No-Wait)和2PL(Wait-Die),其实现遵循了[2,3]中对这两种协议的描述:
5.1.1 2PL(No-Wait)
该协议规定,当事务尝试加锁时发现锁冲突,则回滚当前正在请求锁的事务。被回滚的事务已持有的锁都将被释放,从而允许其他事务获得锁。No_Wait机制可以避免死锁,因为事务间的等待不会成环。但是,并非每次出现锁冲突都会导致死锁,因此回滚率可能较高。
5.1.2 2PL(Wait-Die)
Rosenkrantz[3]提出2PL(Wait-Die),用事务开始时间戳作为优先级,来保证锁的等待关系与时间戳顺序一致。只要事务时间戳比当前拥有锁的任何事务小(旧),当前事务需要等待;否则,当前事务需要回滚。对于任意两个冲突事务Ti和Tj,该协议使用时间戳优先级来决定是否让Ti等待Tj,如果Ti优先级更低(时间戳更小)那么Ti需要等待,否则Ti回滚。因而锁等待图里不会构成环,该方法可以避免死锁的发生。该算法是TO和Locking技术的融合。
但是,利用2PL的原理实现的分布式事务处理机制,要么避免死锁(回滚率大),要么需要解决死锁的问题(资源死锁和通信死锁)。在分布式系统中解决死锁的代价会很大(单机系统上解决死锁的代价已经很大,基于多进程或多线程架构的现代数据库系统,解决死锁操作可能导致系统几乎停止服务。如MySQL5.6、5.7版本中对同一个数据项并发更新,死锁检测操作机会导致系统几乎停止服务)。
不仅是死锁检测会消耗巨大资源,锁机制本身带来的弊端一直为人诟病。文献[5]认为封锁机制的弊端如下(对这些弊端的清晰认识,促使文献[5]的作者设计了OCC,Optimistic Concurrency Control,乐观并发访问控制):
1. 封锁机制开销大:为保证可串行性,加锁协议对于不改变数据库完整性约束的只读事务,需要加读锁互斥并发写操作,以防止别人修改;对于可能造成死锁的加锁协议还需要忍受死锁预防/死锁检测等机制带来的开销。
2. 封锁机制复杂:为了避免死锁,需要定制各种复杂的加锁协议(如什么时候加锁、什么时候才能释放锁,怎么保证严格性等)。
3. 降低系统的并发吞吐量:
a)在等待I/O操作的一个事务持锁,将大幅降低系统整体的并发吞吐量。
b)事务回滚完成前,加锁事务回滚时必须持有锁,直到事务回滚结束,这也将降低了系统整体的并发吞吐量。
另外,使用锁的机制进行互斥操作,对于操作系统而言,会引发耗时的内核态操作而使得锁机制的效率低下。这意味着基于操作系统的锁机制的带有事务处理语义的2PL技术更加不可采用(但也有一些技术在不断改进基于封锁协议的并发访问控制算法)。
5.2 时间戳排序协议(T/O)
时间戳排序协议(TimestampOrdering, T/O)在事务开始时,为事务分配时间戳,并按照时间戳的顺序对事务进行排序[2]。当某一操作的执行会违背事务之间已经规定的顺序时,当前操作所在的事务会被回滚或进入等待状态。
3TS中的T/O算法实现遵循[2]中第4.1节的描述,可详细参考该文献获得更多内容。如下图,给出了一个基本的T/O算法的实现。

图4 T/O算法
5.3 多版本并发控制协议(MVCC)
多版本并发访问控制 (Multi-version ConcurrencyControl, MVCC) 是目前的数据库管理系统普遍采用的并发访问控制技术,其首先在 1978 年由 David Patrick Reed [4]提出,其主要思路是将一个逻辑数据项扩充为多个物理版本,将事务对数据项的操作转换为对版本的操作,从而提高事务处理的并发度,并可以提供读写互不阻塞的能力。
Multi version concurrent access control,多版本并发访问控制技术,简称MVCC技术。
1970年MVCC技术被提出,1978年的[4]《Naming andsynchronization m a decentralized computer system》进一步描述,之后在1981年文献[16]详细描述了MVCC技术,但是其描述的MVCC技术是基于时间戳的MVCC。
Multiversion T/O
:For rw synchronization the basic T/Oscheduler can be improved using multiversiondata items [REED78]. For each data item x there is a set of R-ts’sand a set of (W-ts, value) pairs, called versions. The Rts’s of x record thetimestamps of all executed dm-read(x) operations, and the versions record thetimestamps and values of all executed dm-write(x) operations. (In practice onecannot store R-ts’s and versions forever; techniques for deleting old versionsand timestamps are described in Sections 4.5 and 5.2.2.)
之后,MVCC技术被大量使用并衍生出多种版本。
2008年,文献[13]发表,提出“SerializableSnapshot Isolation”技术实现基于MVCC的可串行化隔离级别。这使得PostgreSQL V9.1使用该技术实现了可串行化隔离级别。
2012年,文献[14]发表,提出“Write-snapshotIsolation”技术通过验证读写冲突实现基于MVCC的可串行化隔离级别,相较于依靠检测写写冲突的方式提高并发度(某种写写冲突是可串行化的)。该文作者基于HBase做了系统实现。
2012年,文献[17]在PostgreSQL实现了SSI技术。该文献不仅讲述了序列化快照的理论基础、PostgreSQL对于SSI技术的实现方式,还提出了为支持只读事务而实现的“Safe Snapshots”、“Deferable Transaction”,因为避免读-写冲突造成事务回滚的影响而对被回滚的事务采取“safe retry”策略,以及两阶段提交对选取回滚读-写冲突的事务的影响等重要话题。
文献[19]较为系统地讨论了MVCC技术涉及地四个方面,分别是:并发访问控制协议、多版本存储、旧版本垃圾回收、索引管理,另外讨论了MVCC的多种变体的原理,实现多种变体(MV2PL、MVOCC、MVTO等)后在OLTPworkload上测试评估各个变体的效果。[18]则对于MVCC的旧版本垃圾回收进行了详细讨论。
3TS中,主要基于[2]中第4.3节的描述,结合T/O算法实现了MVCC。因此,事务间仍然使用开始时间戳进行排序,与传统T/O算法不同的是,MVCC利用多版本的特性,可以减少T/O中的操作等待开销。MVCC中的操作执行机制如下(用ts代表当前事务的时间戳):
1. 读操作
a) 如果ts大于prereq中所有事务的时间戳,且在writehis(当前数据项的版本链)中存在一个版本,其wts大于ts且小于pts,则当前版本可以返回,且将当前事务的时间戳存入readhis。如果writehis不存在对应的时间戳,则将当前事务的时间戳存入readreq。主要原因为:
如果在预写事务和读操作之间存在一个已经提交的写,那么代表当前读操作读到的数据是已经提交写事务写入的,满足时间戳排序,可以读到该版本;
读操作的时间戳比当前未完成的写事务的时间戳大,应该读到新数据,所以要等待;
b) 否则,当前读操作通过时间戳读到最新可见版本,并将当前事务的时间戳存入readreq;
2. 写操作
a) 如果ts小于readhis中所有事务的时间戳,且在writehis中存在一个时间戳在rts和ts之间,可以正常预写数据。如果writehis中不存在符合条件的版本,那么当前事务回滚;
b) 将当前写操作暂存在prereq_mvcc中;
3. 提交操作
a) 将当前事务时间戳和写入的新版本插入writehis;
b) 从prereq中把当前事务的写操作删除;
c) 继续执行readreq中满足时间戳顺序的读事务;
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777