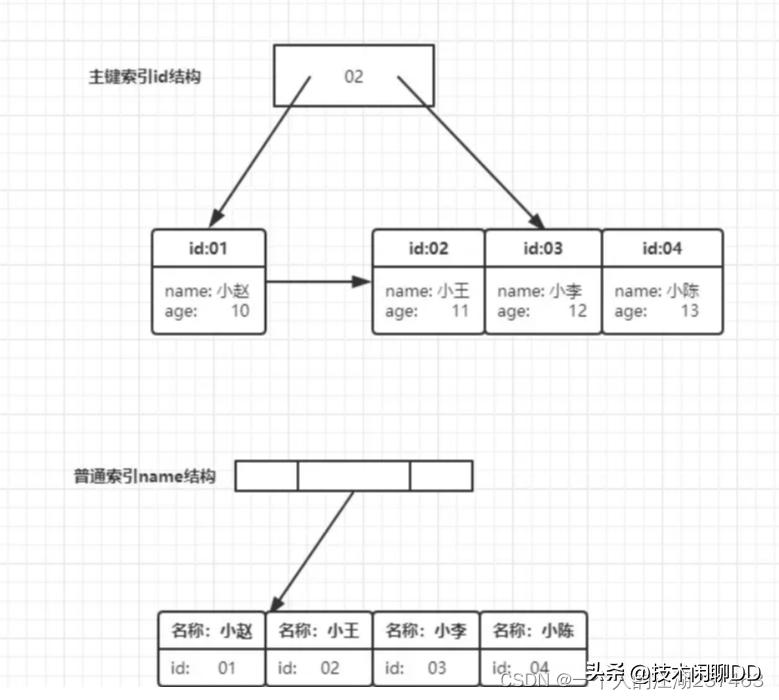
索引本质是一棵B+Tree,联合索引(col1, col2,col3)也是。
其非叶子节点存储的是第一个关键字的索引,而叶节点存储的则是三个关键字col1、col2、col3三个关键字的数据,且按照col1、col2、col3的顺序进行排序。
(图以innodb引擎为例,对应地址指的是数据记录的地址)
联合索引(年龄, 姓氏,名字),叶节点上data域存储的是三个关键字的数据。且是按照年龄、姓氏、名字的顺序排列的。
而最左原则的原理就是,因为联合索引的B+Tree是按照第一个关键字进行索引排列的。
下面举个例子:
联合索引
简要地说就是由多个字段组成的索引,假设现在有张市民信息表T
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=I里面有身份证号 id_card、姓名 name等字段,有个高频请求:根据身份证号查询姓名,那么我们就可以创建 (id_card, name) 联合索引,这里会用到覆盖索引,不再需要回表查询整行记录。索引的维护是有代价的,怎样建立联合索引需要考虑具体的业务场景。
最左前缀原则
有时候我们会遇到不常见的查询请求,比如根据身份证号查询市民的家庭住址。如果我们走全表扫描效率太低,单独创建一个索引又浪费空间,这会就可以用B+树索引的最左前缀原则。用联合索引 (name, age) 来说明这个概念:
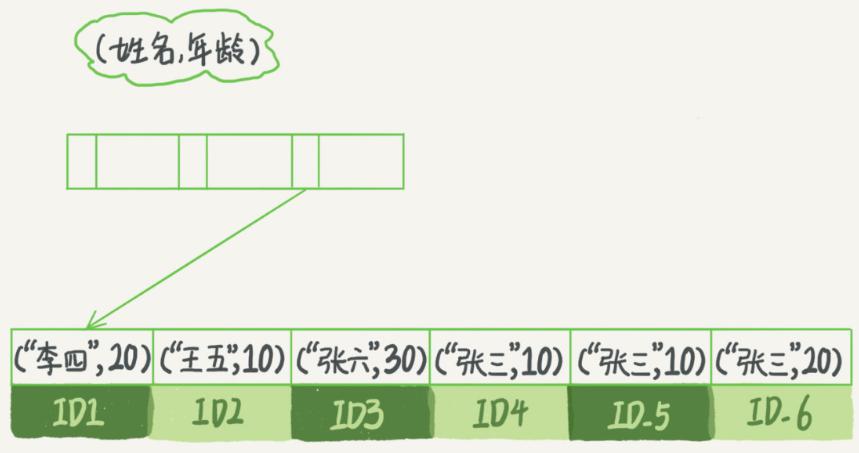
比如需求是查询所有名字是张三的人,可以快速定位到 ID4,然后向后扫描所有满足条件的数据。如果查询姓张的人,sql里条件部分可以这样写 “ where name like ‘张%’ ”,同样也能用到上面的联合索引。这里最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。
那我们该如何建立联合索引呢?首先要遵循一个原则:如果通过调整索引顺序,可以少维护一个索引,那么这个顺序就是优先考虑的。比如上面的(id_card,name)索引,根据 id_card 查询家庭住址就不要再建立 联合索引了。
如果既有联合查询,又有基于a、b各自的查询,比如查询语句中只有索引b是不能用联合索引 (a,b)的。那么就要建立两个索引,考虑的原则是索引占用空间。比如市民信息表中 name 字段比 age 占用空间大,就创建一个 (name, age)联合索引和一个 (age)的单字段索引。
对于联合索引,还有一个问题:字段中不符合最左前缀的部分会怎么样?同样用上面的 (name, age) 索引来说明,现在有一个需求:“查询出名字第一个字是张,年龄为10岁的男孩”。sql是这样的:
select * from T where name like '张%' and age = 10 and ismale = 1;在MySQL5.6之前,只能不停地回表查到最后的结果;5.6之后引入了索引下推优化,就是在索引遍历过程中,对索引中包含的字段中先做判断,过滤掉不满足条件的记录,减少回表的次数。用两个图来解释:分别是优化前后
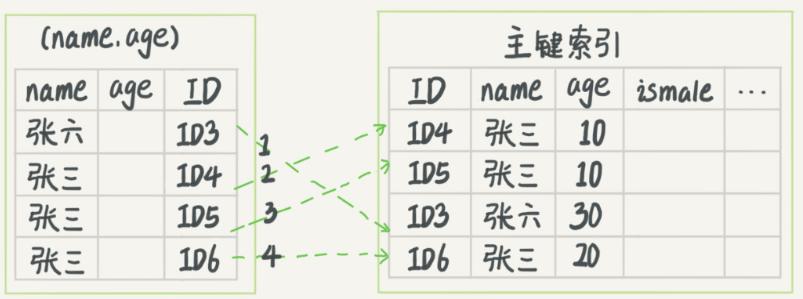
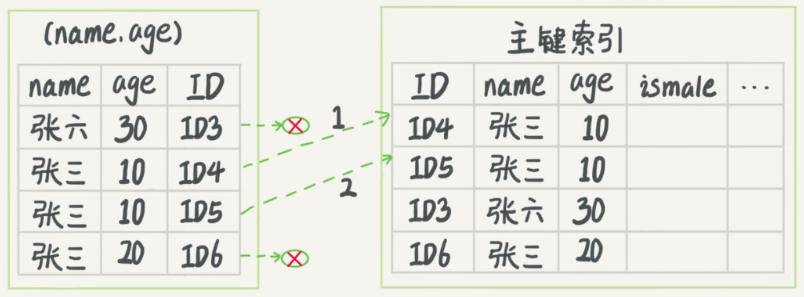
是4次回表,优化后变成2次,减少了对资源的访问。
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777