

进程内的多个线程共享同一虚拟地址空间,每个线程都是一个独立的执行流,所以,多个线程对应多个执行流,多个执行流会竞争同一资源的情况,资源包括内存数据、打开的文件句柄、套接字等,如果不加以控制和协调,则有可能出现数据不一致,而这种数据不一致可能导致结果错误,甚至程序奔溃,因此,需要努力避免。
并发编程的错误非常诡谲且难以定位,它总是隐藏在某个的角落,大多数时候,程序运转良好,等代码交付上线后,莫名其妙的出错,就像墨菲定律描述的那样:凡是可能出错,就一定会出错。
数据不一致源于什么?
CPU与内存访问性能差距很大,Cache被作为内存的缓存插入到CPU与内存之间,数据会在Cache里缓存内存数据的副本,内存数据与缓存数据不总是一致。比如修改变量(写入数据),如果采取写穿透(Write Through)的方式,则会在更新缓存中对应的Cache Line的同时把数据写入内存,如果数据不在缓存,则直接写入内存,但每次写操作都写入内存,而内存的访问时延通常高达几十个指令周期,这种写的方式性能太低。而采用写回(Write Back)的方式,如数据在Local Cache里,则更新缓存后就直接返回,这样就减少访问内存的频率,也就提升了性能,但这样的话,内存数据和Cache里的数据是不一致的。
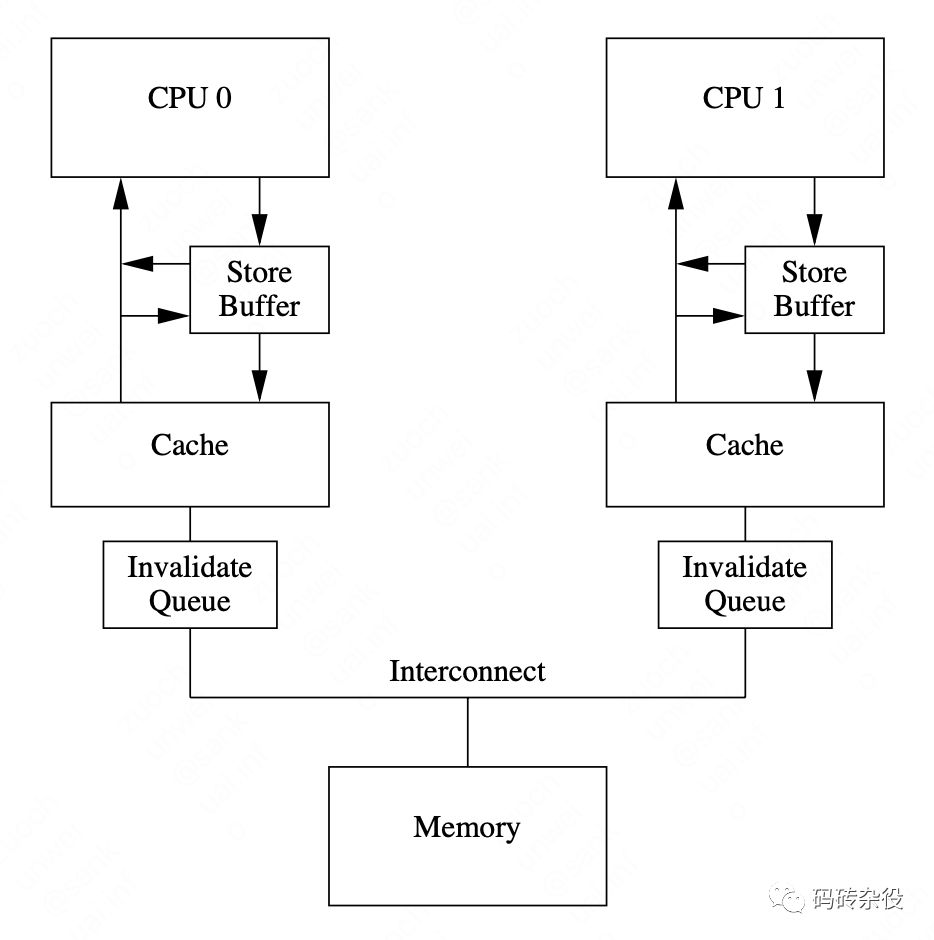
现代处理器朝着多CPU多核架构发展,每个核有自己的L1/L2 Cache ,核之间共享L3 Cache,然后再通过总线连接内存,内存被所有CPU/Core所共享,所以,一个内存数据会被多个CPU/Core Cache,不仅内存与Cache中的数据可能不一致,Cache里的多份拷贝也会不一致,Cache一致性协议用于处理这个问题。
CPU如何使用内存数据?
– CPU通常不会直接操作内存
– 这是因为有些指令对操作数有限制,比如X86-64限制mov指令的源和目的操作数不能都是内存地址,所以把一个字节从一个内存地址复制到另一个内存地址,需要两条mov汇编指令,先从源地址move到寄存器,再从寄存器move到目标地址
– 即使mov的一个操作数是内存地址,实际上,CPU处理的时候,也会先将内存地址的数据加载到Cache Line,再作用于Cache Line,而非直接修改内存
– 多CPU多核系统上,如果Core的local Cache没有对应变量的数据,它并不是只有从内存里加载数据到Cache这一条路,而是会通过CPU/Core间消息,从别的CPU/Core的Cache里拿数据的拷贝,这个核间消息不是通过共享的总线传递,而是基于Interconnect的message passing
– 当某个Core更新Local Cache里的数据时,它需要通过CPU/Core间消息把这个写入操作传播到其他Core的Cache,如果其他Core也Cache了这个数据,要让对应Cache Line失效,这个叫写传播(Write Propagation),总线嗅探通过感知到核间消息来实现写传播
– 另外,某个CPU核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串形化(Transaction Serialization),而做到这一点,则需要CPU的缓存更新需要引入‘锁’的概念,多个核心有相同数据的Cache,那么对于数据的更新,只有拿到锁进行,而基于总线嗅探实现的MESI协议就是为了实现事务串行化,如果一个数据在某个Core的Cache Line是独占(Exclusive)状态,则它相当于拿到了自由修改权,如果一个数据被加载到多个Core的Cache,则是Shared的状态,这时候,需要通过向其他核广播请求,Invalidate其他核里的Cache Line才能修改。
为什么需要多线程同步?
我们先用2个例子来描述,如果不做线程同步,程序会出现什么问题。
例子1
有一个货物售卖程序,变量int item_num记录某商品的数量,它被初始值为100(代表可售卖数量为100)。售卖函数检查剩余商品数,如果剩余商品数大于等于售卖数量,则扣除商品件数,并返回成功;否则,返回失败。代码如下:
“`c++
bool sell(int num) {
if (item_num >= num) {
item_num -= num;
return true;
return false;
“`
单线程下,sell函数被多次调用,程序运转良好,结果符合预期,但在多线程环境下,会出错。
为了理解上述代码行为,需要先了解一个基本事实:程序变量存放在内存中,对变量做加减,会先将变量加载到通用寄存器,再执行算术运算(更新寄存器中的值),最后把寄存器的新值存入内存位置。
寄存器里会保存内存变量值的副本,对变量的加减乘除等运算直接作用于副本,而非变量内存位置。不过,如果对变量赋值,则指令会接受一个内存位置作为操作数,指令会直接操作内存位置。
#### 多核并行
– 假设线程t1和线程t2,分别在core1和core2同时执行,t1执行sell(50), t2执行sell(100)。
– 2个线程代表2个执行(指令)流,如果2个执行流同时执行到if (item_num >= num)这一行判断语句。
– 内存位置保存的item_num的值会被分别加载到2个核心的寄存器,因为item的值为100,所以加载到寄存器后也都为100,2个线程的条件检查都顺利通过。
– 线程t1,执行减法运算item_num -= num,参数num为50,结果为100-50=50,更新寄存器。
– 线程t2,执行减法运算item_num -= num,参数num为100,结果为100-100=0,更新寄存器。
– 然后,t1和t2线程先后把各自寄存器里的新值store到内存,后一个线程的store操作会覆盖前值。
– 如果t1线程先store,内存中的item_num被修改为50,t2线程再执行store,内存中的item_num被覆盖,item_num值被替换为0。
– 如果t2线程先store,t1线程后store,则item_num的最终值为50。
无论哪种情况,结果都是错误的,我们只有100件商品,却超卖出150件。
单核并发
– 如果程序在单CPU单Core的机器上运行,t1线程和t2线程并发(非并行)交错执行,因为只有一个CPU,所以同一时刻,只有一个线程在执行。
– 假设t1在CPU上执行,它把item_num(100) load到寄存器,判断通过(100 >= 100)。
– 这时候,发生线程调度(比如t1的时间配额耗尽),t2被调度到CPU上执行,然后t2依次完成load、check、compute和store操作。
– 然后t1又被调度到CPU上恢复执行,t1会直接用寄存器中的item_num副本(100),执行计算,item -= 50的结果为50,更新寄存器,所以t1线程执行后,新值50被store入item_num所在内存。
– 我们期望t1或者t2的sell只有一个操作成功,但结果并非如此。
CPU核相当于工人,而程序线程相当于任务,核的数量决定了并行度,多个核代表多个任务可以被同时执行,但多线程竞争导致数据的不一致,在单核环境也有可能出现。
让我们再看一个计数的例子:
例子2
全局变量int count用来计数,我们启动100个线程,每个线程的处理逻辑:在100次循环里累加count;主函数启动线程并等待所有线程执行完成,程序退出前打印count数值,代码如下:
“`c++
#include
#include
int count = 0;
void thread_proc() {
for (int i = 0; i < 100; ++i) {
++count;
int main() {
std::thread threads[100];
for (auto &x : threads) {
x = std::move(std::thread(thread_proc));
for (auto &x : threads) {
x.join();
std::cout
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777



