问题描述
某天下午运维反馈说我们这一个pod一天重启了8次,需要排查下原因。一看 Kibana 日志,jvm 没有抛出过任何错误,服务就直接重启了。显然是进程被直接杀了,初步判断是 pod 达到内存上限被 K8s oomkill 了。
Containers:container-prod--:Container ID: --Image: --Image ID: docker-pullable://--Port: 8080/TCPHost Port: 0/TCPState: RunningStarted: Fri, 05 Jan 2024 11:40:01 +0800Last State: TerminatedReason: ErrorExit Code: 137Started: Fri, 05 Jan 2024 11:27:38 +0800Finished: Fri, 05 Jan 2024 11:39:58 +0800Ready: TrueRestart Count: 8Limits:cpu: 8memory: 6GiRequests:cpu: 100mmemory: 512Mi可以看到 Last State:Terminated,Exit Code: 137。这个错误码表示的是 pod进 程被 SIGKILL 给杀掉了。一般情况下是因为 pod 达到内存上限被 K8s 杀了。
因此得出结论是生产环境暂时先扩大下 pod 的内存限制,让服务稳住。然后再排查为啥 pod 里会有这么多的堆外内存占用。
进一步分析
但是运维反馈说无法再扩大 pod 的内存限制,因为宿主机的内存已经占到了99%了。
然后结合pod的内存监控,发现pod被杀前的内存占用只到4G左右,没有达到上限的6G,pod 就被 kill 掉了。
于是问题就来了,为啥 pod 没有达到内存上限就被kill了呢。
带着疑问,我开始在google里寻找答案,也发现了一些端倪:
谜题解开
最终还是google给出了答案:
Why my pod gets OOMKill (exit code 137) without reaching threshold of requested memory
链接里的作者遇到了和我一样的情况,pod还没吃到内存上限就被杀了,而且也是:
Last State: TerminatedReason: ErrorExit Code: 137作者最终定位的原因是因为k8s的QoS机制,在宿主机资源耗尽的时候,会按照QoS机制的优先级,去杀掉pod来释放资源。
什么是K8s的QoS?
QoS,指的是Quality of Service,也就是 K8s 用来标记各个pod对于资源使用情况的质量,QoS会直接影响当节点资源耗尽的时候k8s对pod进行evict的决策。官方的描述在这里。
K8s会以pod的描述文件里的资源限制,对pod进行分级:
当节点资源耗尽的时候,k8s会按照BestEffort->Burstable->Guaranteed这样的优先级去选择杀死pod去释放资源。
从上面运维给我们的pod描述可以看到,这个 pod 的资源限制是这样的:
Limits:cpu: 8memory: 6GiRequests:cpu: 100mmemory: 512Mi显然符合的是Burstable的标准,所以宿主机内存耗尽的情况下,如果其他服务都是Guaranteed,那自然会一直杀死这个pod来释放资源,哪怕pod本身并没有达到6G的内存上限。
QoS相同的情况下,按照什么优先级去Evict?
但是和运维沟通了一下,我们集群内所有pod的配置,limit和request都是不一样的,也就是说,大家都是Burstable。所以为什么其他pod没有被evict,只有这个pod被反复evict呢?
QoS相同的情况,肯定还是会有evict的优先级的,只是需要我们再去寻找下官方文档。
关于Node资源耗尽时候的Evict机制,官方文档有很详细的描述。
其中最关键的一段是这个:
If the kubelet can’t reclaim memory before a node experiences OOM, the oom_killer calculates an oom_score based on the percentage of memory it’s using on the node, and then adds the oom_score_adj to get an effective oom_score for each container. It then kills the container with the highest score.
This means that containers in low QoS pods that consume a large amount of memory relative to their scheduling requests are killed first.
简单来说就是pod evict的标准来自oom_score,每个pod都会被计算出来一个oom_score,而oom_score的计算方式是:pod使用的内存占总内存的比例加上pod的oom_score_adj值。
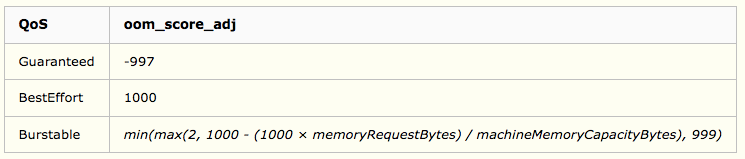
oom_score_adj 的值是 k8s 基于 QoS 计算出来的一个偏移值,计算方法:
从这个表格可以看出:
总结
至此已经可以基本上定位出 Pod 被反复重启的原因了:
那么如何解决呢?
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。