2.2 数据 shuffle
在 FTS 中,选择哪些数据作为验证集并非易事。确实,验证集的选择有无数种方法,但对于变化不定的股票指数,必须仔细考虑。
固定原点方法是最朴素也最常用的方法。给出特定的分割大小,将数据前面一部分分割为训练集,后面的部分分割为验证集。但这是一种较为初级的选择方法,对于像亚马逊这样的高增长股票而言尤其如此。之所以会出现这种情况,是因为亚马逊的股价一开始波动性较低,随着股价的增长,股价波动越来越大。
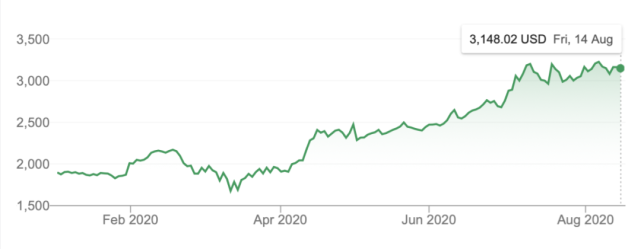
亚马逊今年股票价格(图源:Google Finance)
因此,我们需要训练一个低波动率动态模型,并期望它能预测高波动率动态。对于上述类型的股票而言,这确实有一定困难,并且还要以性能作为代价。因此,如果仅考虑这一点,以验证损失和性能作为基准可能存在一定的误导性。但是,对于像英特尔这样波动性较为稳定的股票(COVID 危机前),这种方法是合理的。
滚动原点重校方法比固定原点方法略稳健,因为它允许通过对数据的多种不同分割取平均值来计算验证损失,以避免无法代表高波动率时间段的问题。
最后,滚动窗口方法通常是最有用的方法之一,因为它尤其适用于长时间运行的 FTS 算法。实际上,该模型输出多个滚动数据窗口的平均验证误差。而这意味着最终获得的值更能代表最近的模型性能。
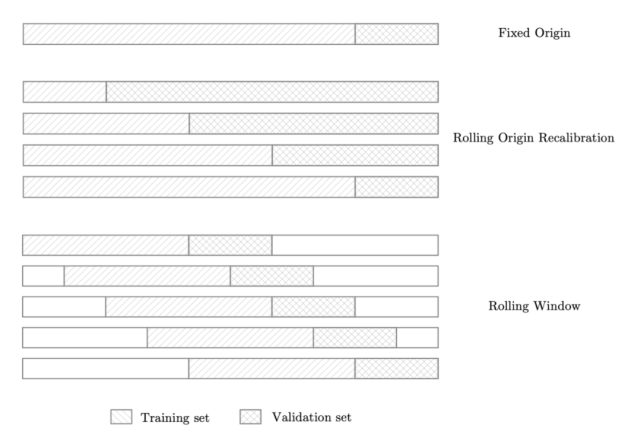
数据 shuffle 技术可视化(图源:)
Thomas Hollis 等人的研究表明,滚动窗口(RW)和滚动原点重校(ROR)的性能(58%和 60%)都比简单的固定原点方法好。这表明对于像亚马逊这样的高波动率股票,使用这些数据 shuffle 方法是不可避免的。
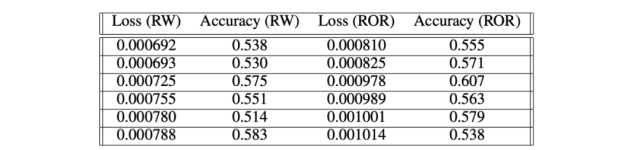
数据 shuffle 方法性能比较
3. 时间卷积网络
时间卷积网络(TCN),是用于序列建模任务的卷积神经网络的变体,结合了 RNN 和 CNN 架构。对 TCN 的初步评估表明,简单的卷积结构在多个任务和数据集上的性能优于典型循环网络(如 LSTM),同时表现出更长的有效记忆。
TCN 的特征是:
1. TCN 架构中的卷积是因果卷积,这意味着从将来到过去不存在信息「泄漏」;
2. 该架构可以像 RNN 一样采用任意长度的序列,并将其映射到相同长度的输出序列。通过结合非常深的网络(使用残差层进行增强)和扩张卷积,TCN 具有非常长的有效历史长度(即网络能够看到很久远的过去,并帮助预测)。
3.1 TCN 模型架构概览
3.1.1 因果卷积
如前所述,TCN 基于两个原则:网络的输入输出长度相同,且从未来到过去不存在信息泄漏。
为了完成第一点,TCN 使用 1D 全卷积网络(FCN),每个隐藏层的长度与输入层相同,并用零填充(长度为 kernel size − 1)来保持后续层与之前层长度相同。为了实现第二点,TCN 使用因果卷积,即卷积中时间 t 处的输出仅与时间 t 或前一层中的元素进行卷积。
简而言之:TCN = 1D FCN + 因果卷积。
3.1.2 扩张卷积
简单的因果卷积回看的历史长度只能与网络深度呈线性关系。这使得将因果卷积应用于序列任务具有一定难度,尤其是需要更长历史的任务。Bai 等人采用扩张卷积找到了一种解决方案,其感受野呈指数级增大。对于一维序列输入 x ∈ R^ⁿ 和滤波器 f:→R,序列元素 s 的扩张卷积运算 F 可定义为:
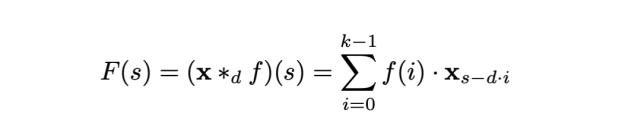
其中 d 是扩张因子,k 是滤波器大小,s-d·i 代表过去的方向。因此,扩张卷积等效于在每两个相邻的滤波器之间引入一个固定的步长。当 d = 1 时,扩张卷积即为常规卷积。而使用较大的扩张因子,可使顶层的输出表示更大范围的输入,从而有效地扩展了 ConvNet 的感受野。
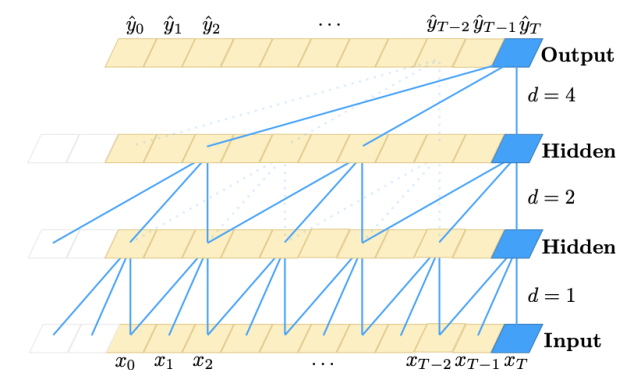
扩张因果卷积,扩张因子 d = 1、2、4,滤波器大小 k =3。感受野能够覆盖输入序列中的所有值。
3.1.3 残差连接
残差模块可使层高效学习修改(modification),进而识别映射而不是整个变换,这对非常深的网络很有用。
由于 TCN 的感受野取决于网络深度 n、滤波器大小 k 和扩张因子 d,因此,对于更深更大的 TCN 来说,稳定性很重要。
3.2 TCN 的优缺点
使用 TCN 进行序列建模具备以下优势:
并行性。与 RNN 中后继时间步长的预测必须等待之前时间步完成预测不同,卷积可以并行完成,因为每一层都使用相同的滤波器。因此,在训练和评估中,TCN 可以处理一整个较长的输入序列,而不是像 RNN 中那样顺序处理。
灵活的感受野大小。TCN 有多种方式更改其感受野大小。例如,堆叠更多扩张(因果)卷积层,使用更大的扩张因子,或增加滤波器大小都是可行的选择。因此,TCN 可以更好地控制模型的内存大小,它们也可以轻松适应不同的域。
梯度稳定。与循环网络不一样的是,TCN 的反向传播路径与序列的时间方向不同。TCN 因此避免了梯度爆炸 / 消失问题,这是 RNN 面临的主要问题(限制了 LSTM 和 GRU 的发展)。
训练内存需求低。特别是在输入序列较长的情况下,LSTM 和 GRU 占用大量内存存储其多个单元门的部分结果。然而,在 TCN 中,滤波器是跨层共享的,而反向传播路径仅取决于网络深度。因此,在实践中,人们发现门控 RNN 比 TCN 消耗的内存更多。
可变长度输入。RNN 以循环的方式对可变长度输入进行建模,TCN 也可以通过滑动一维卷积核来接收任意长度的输入。这意味着,对于任意长度的序列数据,都可以用 TCN 替代 RNN。
使用 TCN 存在两个明显的缺点:
评估期间的数据存储。TCN 需要接收有效历史长度的原始序列,因此在评估过程中可能需要更多的内存。
域迁移时可能引起参数更改。不同的域对模型预测所需的历史量可能有不同的要求。因此,当将模型从仅需要很少记忆(即较小的 k 和 d)的域转移至需要更长记忆(即较大的 k 和 d)的域时,TCN 可能因为没有足够大的感受野而表现不佳。
3.3 基准
TCN 和循环网络在典型的序列建模任务中的评估结果,这些任务通常用来评估 RNN 模型。
上述结果表明,经过最小调优的通用 TCN 架构在大量序列建模任务中优于典型循环架构,而这些任务通常用于对循环架构的性能进行基准测试。
4. 基于 TCN 的知识驱动股市趋势预测与解释
4.1 背景介绍
用于股市趋势预测的大部分深度神经网络存在两个常见缺陷:1)当前方法对股市趋势的突然变化不够敏感;2)预测结果不具备可解释性。
为了解决这两个问题,Deng 等人 2019 年提出一种新型知识驱动时间卷积网络(KDTCN)用于股市趋势预测和解释,该方法将背景知识、新闻事件和股价数据集成到深度预测模型中,以解决股市趋势突变时的趋势预测和解释问题。
为了解决股市趋势突变下的预测问题,该研究将金融新闻中的事件提取出来并结构化为事件元组,如「Britain exiting from EU」被表示为 (Britain, exiting from, EU)。然后将事件元组中的实体和关系链接至知识图谱(KG),如 Freebase 和 Wikidata。接下来,分别对结构化知识、文本新闻和股价数值进行向量化和级联。最后,将这些嵌入馈入基于 TCN 的模型。
实验表明 KDTCN 可以更快地响应股市突变,在股市数据集上的性能优于 SOTA 方法,此外它还增强了股市突变预测的可解释性。
此外,基于股市突变预测结果,要想解决可解释性问题,我们可以通过知识图谱中事件的关联对事件的影响进行可视化。这样,我们就可以解释 1)知识驱动的事件如何不同程度地影响股市波动;2)知识如何将股市趋势预测中与突变相关的事件关联起来。
4.2 KDTCN 模型架构
这里介绍的基础 TCN 模型架构基于第三部分推导而来,通用 TCN 架构包括因果卷积、残差连接和扩张卷积。
KDTCN 架构如下所示:
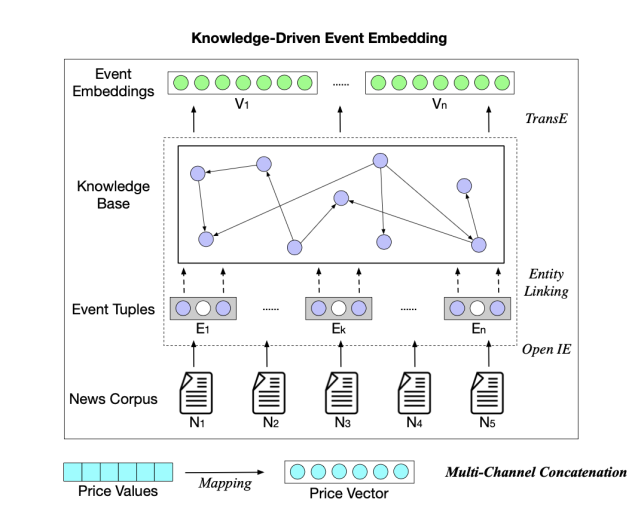
KDTCN 框架图示
原始模型输入为股价 X、新闻数据库 N 和知识图谱 G。股价经过归一化处理,并映射到股价向量:
其中每个向量 p_t 表示股票交易日 t 的实时股价向量,T 表示时间跨度。
至于新闻数据库,新闻被表示为事件集合 ε,然后被结构化为事件元组 e = (s, p, o),其中 p 为动作 / 谓语、s 是执行者 / 主语、o 是动作承受者。事件元组中的每个项都与知识图谱链接,对应知识图谱中的实体和关系,通过训练事件元组和 KG 三元组获得事件嵌入 V。详细过程参见 。
最后,将事件嵌入和股价向量结合并输入基于 TCN 的模型。
4.2.1 数据集和基线
数据集:
1. 时间序列股价数据 X:道琼斯工业平均指数每日记录构成的股价数据集;
2. 文本新闻数据 N:来自 Reddit WorldNews 频道的历史新闻组成的新闻数据集;
3. 结构化知识数据 G:基于两个常用开放研究知识图谱 Freebase 和 Wikidata 的结构化数据构建的子图。
基线:
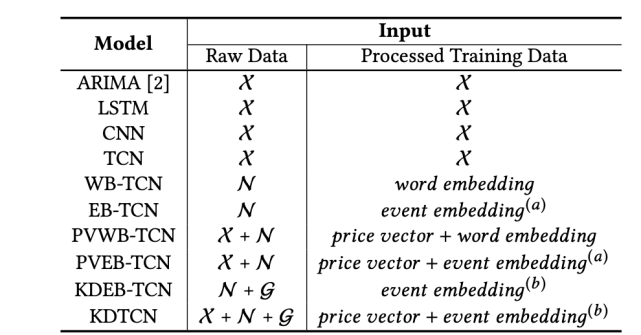
使用不同输入的基线模型。第一列中,前缀 WB 表示词嵌入,EB 表示事件嵌入,PV 表示股价向量,KD 表示知识驱动。注意,event embedding^(a) 和 event embedding^(b) 分别表示不具备 / 具备 KG 的事件嵌入。
4.3 预测评估
KDTCN 的性能评估基于以下三个方面:1)基础 TCN 架构的评估;2)不同模型输入对 TCN 的影响;3)基于 TCN 的模型对股市趋势突变的预测性能。
基础 TCN 架构:
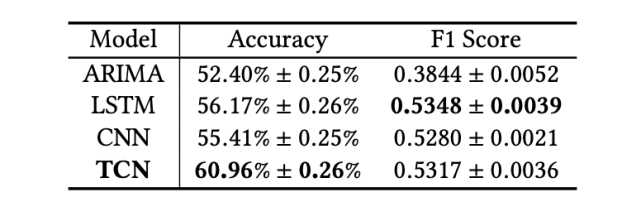
在道琼斯工业平均指数数据集上,不同基础预测模型的股市趋势预测结果。
TCN 在股市趋势预测任务上超过其他基线模型,不管是传统的机器学习模型 (ARIMA) 还是深度神经网络(如 LSTM 和 CNN),这说明 TCN 在序列建模和分类问题上有更明显的优势。
不同模型输入:
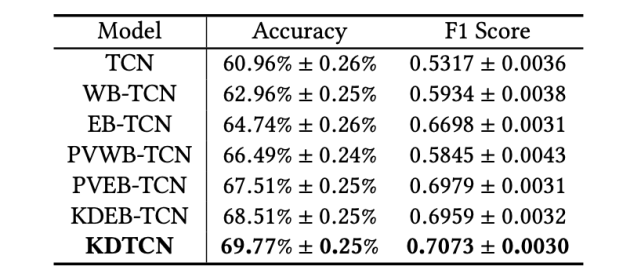
在道琼斯工业平均指数数据集上,不同输入的 TCN 模型的股市趋势预测结果。
可以看出,WB-TCN 和 EB-TCN 的性能都超过 TCN,这表明文本信息有助于改进预测结果。
KDTCN 获得了最高的准确率和 F1 得分,这说明模型输入集成结构化知识、金融新闻和股价信息是有效的。
模型对股市趋势突变的预测性能:
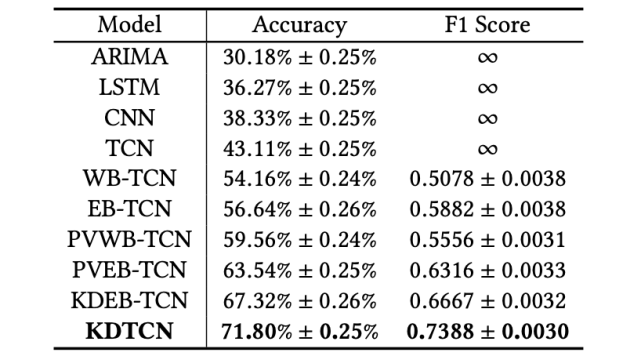
基于局部道琼斯工业平均指数数据集(股市趋势突变),不同输入的模型的股市趋势预测结果。
可以看出,使用知识驱动事件嵌入输入的模型(如 KDEB-TCN 和 KDTCN)性能大大超过基于数值数据和文本数据的模型。这些对比结果说明,知识驱动的模型对于股市突变能够做出更快的反应。
那么,如何量化股市波动程度呢?
首先,通过识别两个邻近股票交易日的波动程度 D_(fluctuation) 获取股市突变的时间间隔:
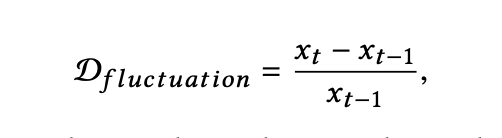
其中时间 t 处的 x 表示股票交易日 t 的股票价格。波动程度的差异 C 被定义为:
如果 | Ci | 超过特定阈值,则可以认为在第 i 天,股票价格突变。
4.4 解释预测结果
为什么知识驱动事件是不具备 ML 专业知识的人识别股市突变的常规来源?这可以从两个方面进行解释:1)将知识驱动事件对突变预测结果的影响可视化;2)将知识驱动事件链接至外部 KG,进而检索事件的背景事实。
将知识驱动事件的影响可视化:
下图中的预测结果显示道琼斯工业平均指数趋势将下降。注意图中同色长条表示相同的事件影响,长条的高度反映了影响的程度,事件的流行性自左向右下降。直观来看,具备更高流行性的事件对股市趋势突变预测应有更大的影响,但事实并不总是如此。
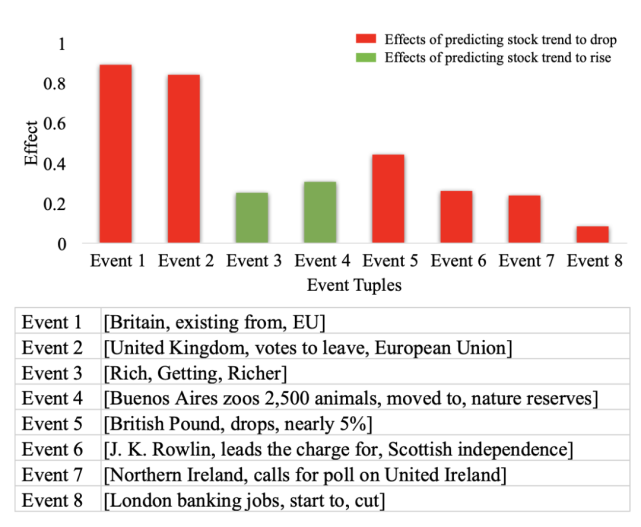
事件对股市趋势预测的影响示例。
几乎所有负影响事件都与这两个事件有关,如 (British Pound, drops, nearly 5%) 和 (Northern Ireland, calls for poll on United Ireland)。
尽管一些事件对预测股市趋势上涨有着积极影响也具备高流行性,但整体影响仍是负面的。因此,股票指数波动出现突变可被视为事件影响和事件流行性的共同结果。
事件元组链接至 KG 后的可视化结果:
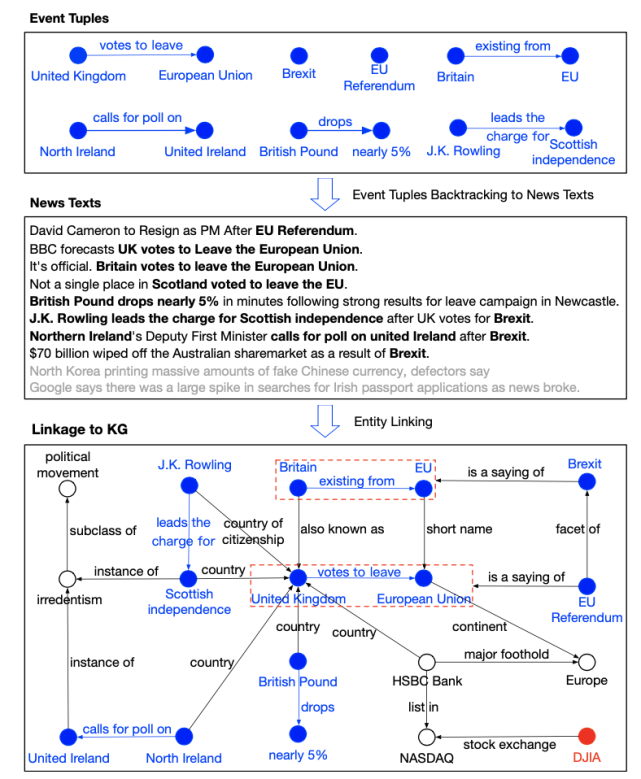
首先,搜索具备高影响或高流行性的事件元组;然后,回溯包含这些事件的新闻文本;最后,通过实体链接检索与事件元组相关的 KG 三元组。上图中,蓝色为事件元组,其中的实体与 KG 链接。
列出的这些事件元组字面上并没有强相关。但是,链接 KG 后,它们可以彼此建立关联,并与英国脱欧和欧盟公投事件产生强相关。通过集成事件影响的解释,我们可以证明知识驱动事件是突变的常规来源。
结论
循环网络在序列建模中的优秀效果可能大多是历史的痕迹。最近,扩张卷积和残差连接等架构元素的引入使得卷积架构不那么弱了。近期的学术研究表明,使用这些元素后,简单的卷积架构在不同序列建模任务上的效果优于循环架构,如 LSTM。由于 TCN 的清晰性和简洁性,Shaojie Bai 等人提出卷积网络应被看作序列建模的起点和强大工具。
此外,本文介绍的 TCN 在股市趋势预测任务中的应用表明,集成新闻事件和知识图谱后,TCN 的性能大幅超过 RNN。
参考文献
[1] Hollis, T., Viscardi, A. and Yi, S. (2020). “A Comparison Of Lstms And Attention Mechanisms For Forecasting Financial Time Series”. ()
[2] Qiu J, Wang B, Zhou C. (2020). “Forecasting stock prices with long-short term memory neural network based on attention mechanism”. ()
[3] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. (2020). “Neural Machine Translation By Jointly Learning To Align And Translate”. ()
[4] Bai, S., Kolter, J. and Koltun, V., 2020. “An Empirical Evaluation Of Generic Convolutional And Recurrent Networks For Sequence Modeling”. ()
[6] Deng, S., Zhang, N., Zhang, W., Chen, J., Pan, J. and Chen, H., 2019. “Knowledge-Driven Stock Trend Prediction and Explanation via Temporal Convolutional Network”. ()
[5] Hao, H., Wang, Y., Xia, Y., Zhao, J. and Shen, F., 2020. “Temporal Convolutional Attention-Based Network For Sequence Modeling”. ()
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777