此处仅讨论一种技术方法,不做适用性评判和实际场景解决方案优劣的比较。因为对于数据库高可靠有更完善的解决方案,但是对技术能力和硬件设备要求都是比较高的。此处通过简单的部署、配置;较少的服务器(一主n从;n>=1)即可完成基本的数据库高可靠,并实现读写分离的基础环境。
网络上也有很多主从流方案的介绍,可圈可点,本文旨在更直白的阐述原理及部署过程,适当加入自己的理解,希望能对各位有所启发。
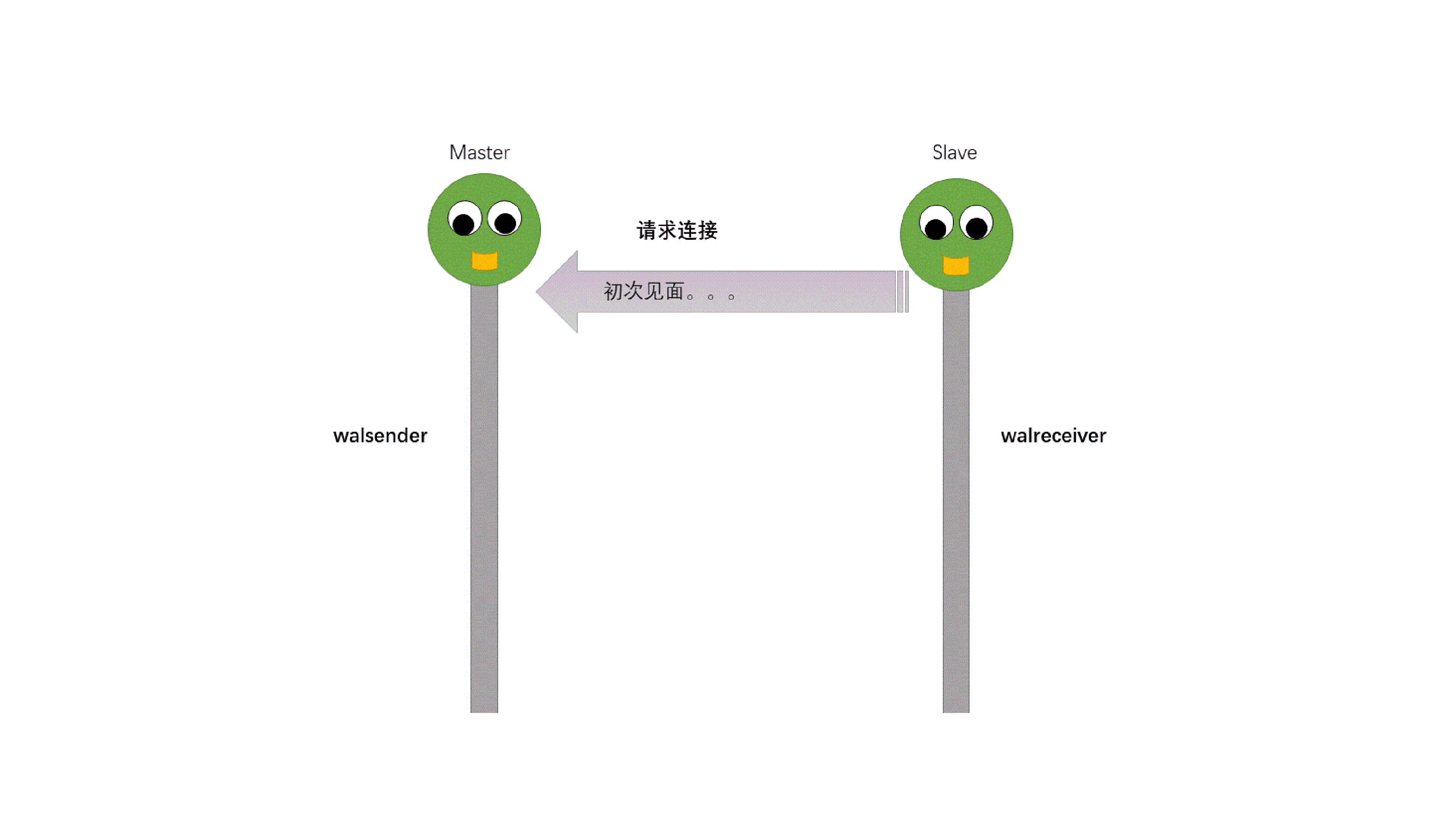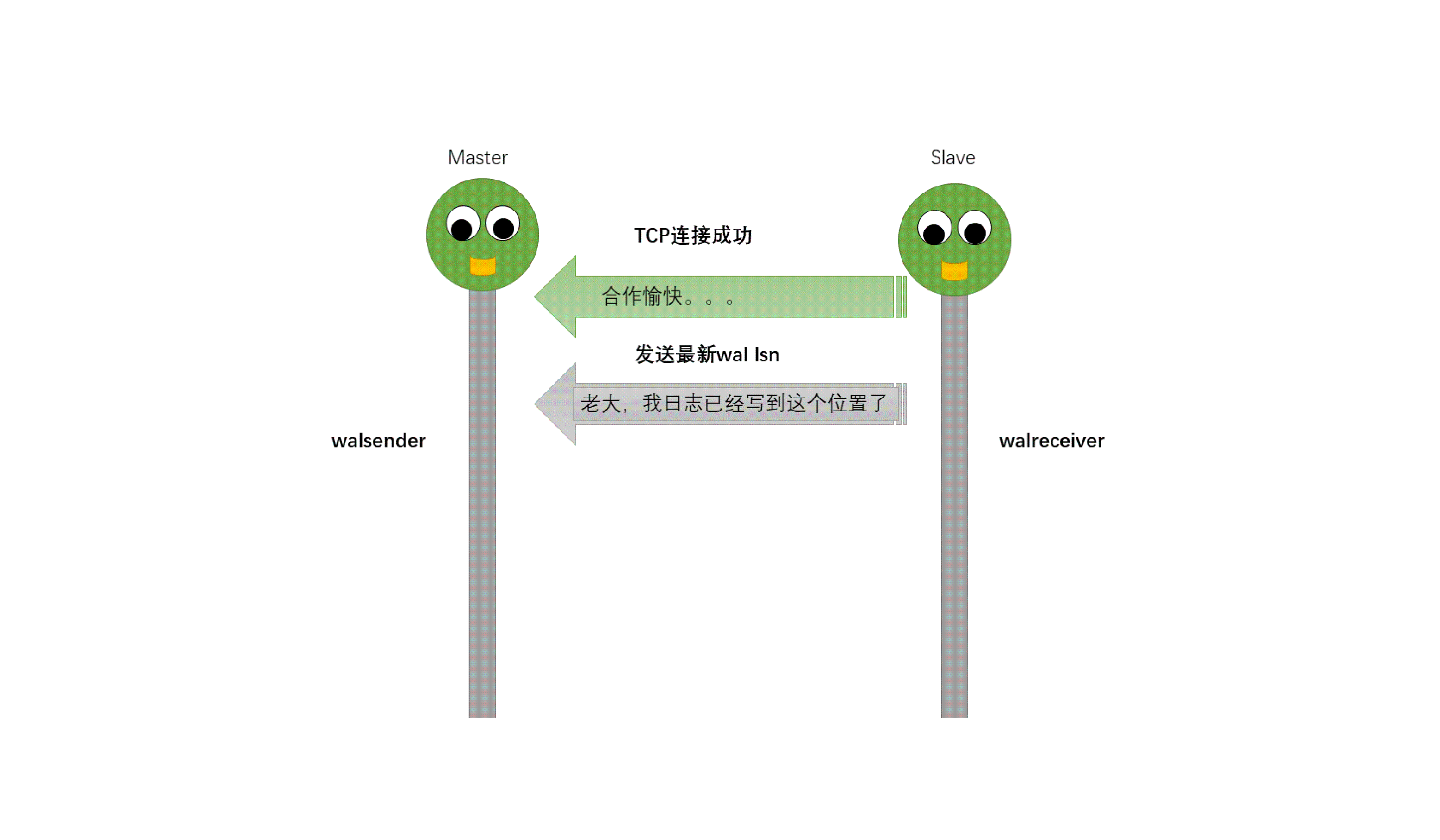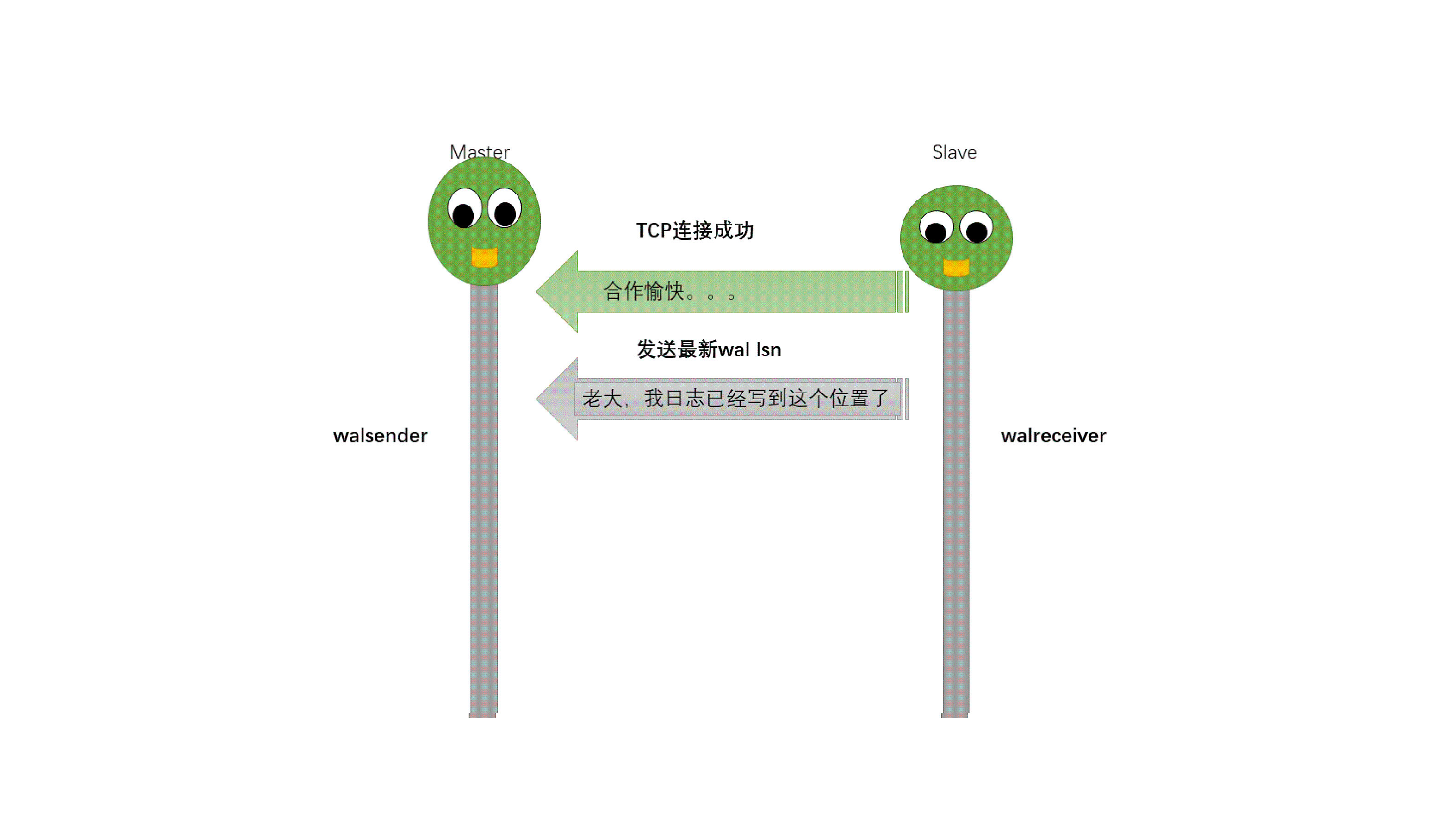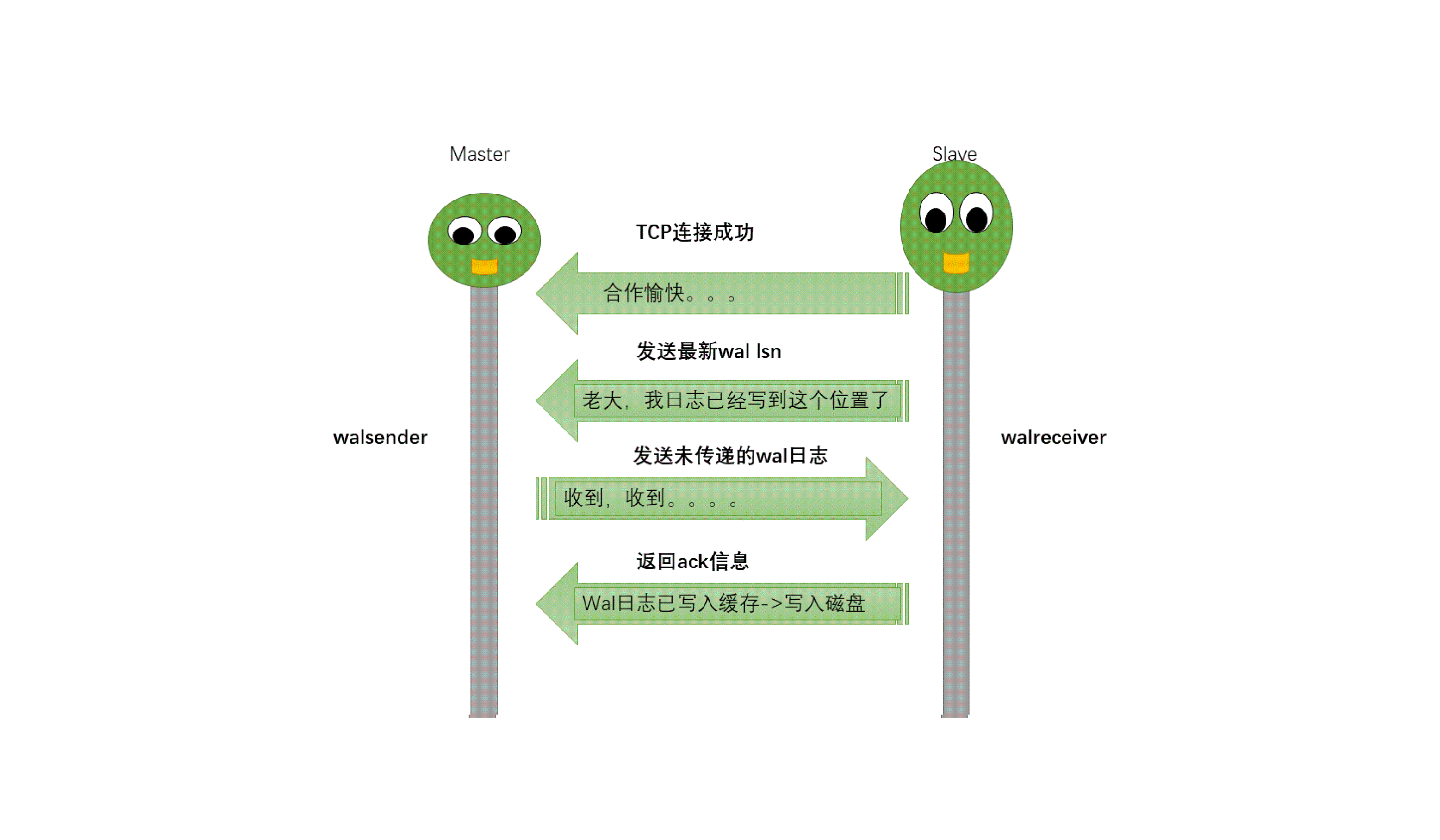
从动图很直观地了解到pg主从流复制过程中主从库交互情况:
主备数据库启动;备库启动walreceiver进程,同时该进程向主库发送连接请求;主库收到连接请求后启动walsender进程,并与walreceiver进程建立tcp连接;备库walreceiver进程发送最新的wal lsn给主库;主库进行lsn对比,将没有传递的wal日志进行发送,同时调用SyncRepWaitForLSN()函数来获取锁存器,并且等待备库响应;备库调用操作系统write()函数将wal写入缓存,然后调用操作系统fsync()函数将wal刷新到磁盘。同时备库向主库返回ack信息,ack信息中包含write_lsn、flush_lsn、replay_lsn,这些信息会发送给主库,用以告知主库当前wal日志在备库的应用位置及状态。主库配置创建同步用户replica
create role replica login replication encrypted password '******';
pg_hba.conf
host all all 从机 ip/32 trust #允许从机连接
host replication replica 从机 ip/32 md5 #允许从机使用 replica 用户来复制,多个从机可配置多行
listen_addresses=’*’ #监听所有 IP
archive_mode= on #允许归档
archive_command = 'cp %p /var/lib/pgsql/10/data/pg_archive/%f' #用该命令归档 logfile segment
wal_level = hot_standby
max_wal_senders = 32 #设置最多有几个流复制连接
wal_sender_timeout=60s#设置流复制发送数据的超时时间
max_connection = 100 #从库 max_connections 必须大于主库的
wal_keep_segments= 5000#设置流复制保留的最多的 xlog 数目
从库配置recovery.conf
standby_mode = on
primary_conninfo = ‘host= 主 机 ip port=5432 user=replica #同步用户连接主库信息
password=replica’
recovery_target_timeline = ‘latest’
postgresql.conf
wal_level = hot_standby
max_connection=1000 #要大于主库配置
hot_standby=on
max_standby_streaming_delay = 30s
wal_receiver_status_interval =10s
hot_standby_feedback = on如果喜欢我的文章,请关注我哦。后续会不断为大家提供干货分享。请及时查收。
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。