


近日,国际人工智能顶会NeurIPS 2020于线上举办。今天,我们介绍的是旷视研究院入选NeurIPS 2020的工作之一,将聚焦于图像检测和分割方法,与大家一同探讨。
旷视研究院抛弃了图像中常用的网格(Grid)结构形式,利用树形结构实现了线性复杂度的高阶关系建模和特征变换。在保证全局感受野的同时,保留物体的结构信息和细节特征。可学习的模块被灵活地应用在了目标检测、语意分割、实例分割和全景分割上。有效地弥补了传统二元关系建模方法的不足之处,从而在更低的复杂度下,即可取得更为显著的性能提升。此外,还提供了高效的GPU实现和PyTorch代码,只需要两行代码即可使用。
传统长距离关系建模方法
为了解决卷积神经网络的有效感受野受限的问题,很多基于视觉上下文建模的方法被提出来。它们大体上可以被分为两类,一类是local-based,一类是global based。
其中local-based通过增大卷积的感受野来实现,包括dilation convolution,deformable convolution,aspp等等。而global based则利用attention机制,通过建模二元关系来获得全局感受野。
然而,这些建模一元或二元关系的方法,无法感知其他物体的影响。例如,当两个同类物体被背景隔离,这对于instance相关的任务而言,期望两者具有较低的相关性。但是,在没有positionencoding的前提下,这些方法会输出较高的相关性。这反映在可视化上,即很难保留物体的细节或者结构化信息。

图1 传统的上下文建模方法分为
local-based(左)和global-based(右)
建模高阶关系的树形特征变换器
为了解决这个问题,旷视研究院提出了一个工作叫Learnable Tree Filter(原文指路:)。
它利用具有丰富细节信息的低层级特征来构建一颗最小生成树,而最小生成树具有一些很好的特性。如图2中右侧,k点和n点分别属于人和车两种不同物体,理想情况下我们希望它们之间具有很低的特征相似度。但是由于空间距离相近,如果只依靠二元关系建模,则很难将两者有效地区分开。
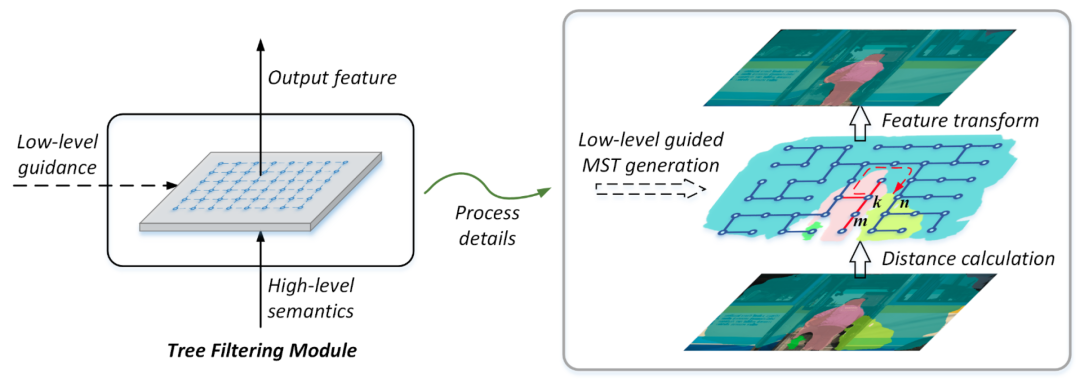
图2 Learnable Tree Filter的示意图。在树上同一物体内不同节点的距离被拉近,而不同物体间的节点则被拉远
而最小生成树的构建过程保证了它会优先连接最相近的节点,也就是说它会先在人和车的内部进行连接,最后再将两者之间进行连接。从而,可以看到图上k到n的红色箭头,它表示的是k到n在树上路径。这个路径的距离等于其中每条边距离的总和,因此能够很好的将两者区分开,从而达到结构保留的效果。
这里区别于传统的二元关系建模,树上k到n的路径是涉及到多节点间的高阶关系,即改变路径中任意一个节点的特征,都会改变k到n之间的相关性。除此之外,由于树是一个无环图,因此可以通过动态规划算法来实现线性的计算复杂度(GPU上实际效率也很高,具体请参考下文)。
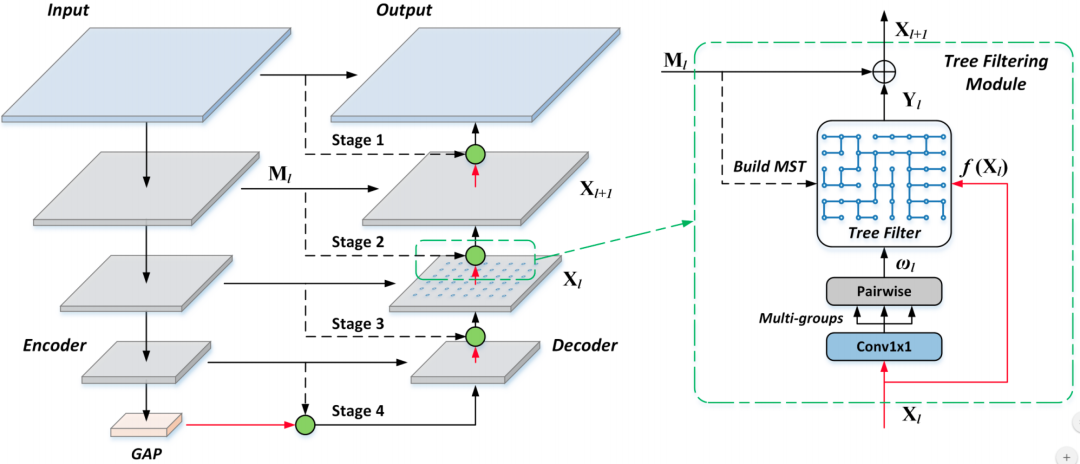
图3 利用Learnable Tree Filter的语义分割网络示意图
我们可以将learnable tree filter打包成了一个可微的即插即用的模块,它可以被很方便地用在各种神经网络的某一层上。例如,对于语义分割任务,我们可以将learnable tree filter也就是图3中的绿圆放在FPN的decoder上。
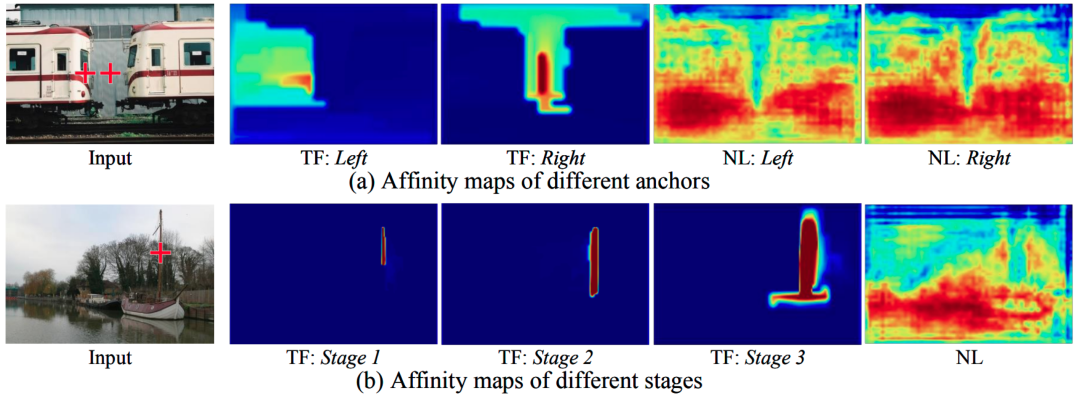
图4 右侧Heatmap表示与一个锚点(红色十字叉)
之间的相关性
图4给出了一些相关性的效果展示,可以看到左边火车上的两个红色十字差表示两个锚点位置,右边的热力图表示与其中一个锚点位置的相似度。可以看到,采用二元关系建模的non-local(右边NL所示)它对两个锚点的相似度几乎一致,而我们的模型则通过建模结构保留的高阶关系,从而有效地将两者进行区分。此外,对于图4中的细长物体(旗杆),二元关系建模的non-local会被背景信息淹没,而我们的方法则可以很好地保留结构细节。
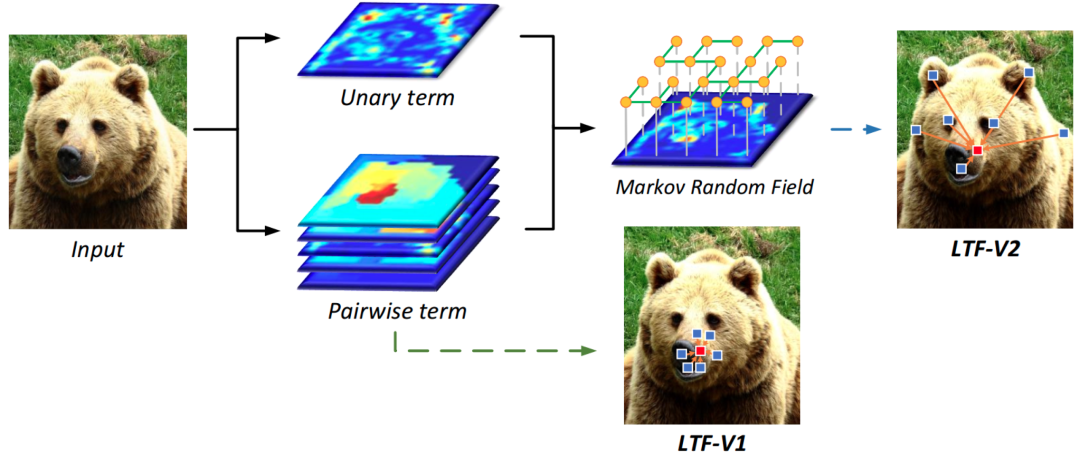
图5 基于改进的Markov Random Field形式的LTF-V2获得了更强大的长距离特征表达能力
然而learnable tree filter依然存在一些问题,由于树自身具有几何约束,导致滤波过程会被限制在一个局部区域内,很难与远方的节点进行有效交互。另外,最小生成树过程是一个不可微的,从而降低了模型的通用性和灵活性。
为了解决第一个问题,我们首先利用MRF对learnable tree filter做了重新的建模,然后我们发现对应的MRF的一元项是一个定值,而这直接导致了learnable tree filter很难具有长距离的感受野。为此,我们引入了一个data-dependent的一元项建模形式。并利用belief propagation算法得到了闭式解,这种新形式的learnable tree filter可以缓解几何约束,并且可以高效地与远方节点进行交互。另外为了解决最小生成树不可微的问题,我们提出了一种可学习的生成树过程,从而实现完全的端到端的训练。
目标检测、语意分割和实例分割的应用

图6 ground-truth、mask-rcnn和learnable tree filter在COCO实例分割的效果图
有了上面的技术,我们看下实际的运行效果。
图6是instance segmentation和object detection的效果图。左边是ground-truth,中间是mask-rcnn的结果,右边是mask-rcnn+learnable treefilter的结果。可以看到learnable tree filter在杯子和勺子的边缘有明显的提升,另外检测和分类能力也得到了增强。

图7learnable tree filter在VOC2012语意分割的效果图
如图7,我们给出了语意分割上的效果,第一行是输入图片,第二行为learnable treefilter的预测,第三行为ground-truth,其中有个非常有意思的现象,比如图中的自行车,可以看到即使ground-truth上没有给出辐条的标注,利用结构保留的建模,我们的算法依然可以将其分割出来。另外,旗杆,马背,马身的细节也可以有效地保留。

表1 各方法在mask-rcnn(resnet-50,1x)下
COCO val set的结果
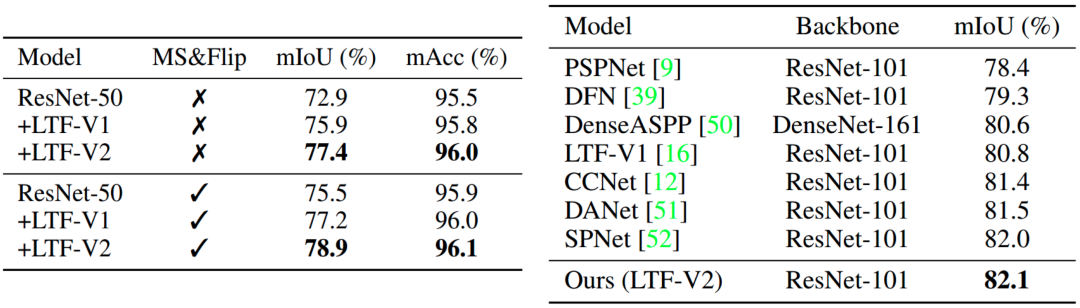
表2 左侧为cityscapes val set
右侧为cityscapes test set,只使用fine数据训练
除此之外,我们这里给出了定量的结果,对于表1中的COCO数据集,我们的算法相对于其他方法,只需要用很少的资源就可以实现更高的性能。对于表2中,cityscapes的语义分割,我们使用简单的FPN结构就可以达到SOTA的结果。
高效灵活,两行PyTorch代码即可使用
图7 在Tesla V100上的实际运行时间
有些人可能会质疑,tree filter这种序列操作在GPU这样的并行设备上效率不高。我们对cuda代码做了仔细地优化,实现batch,channel和同深度节点间的并行,并行效率很好。下图是我们在一块tesla v100的实测结果,可以看到随着节点数的增多,我们的算法实现线性的时间增长,这对于具有大量节点的应用,我们的算法会有很大的优势。
另外,我们还给出了一个很简单的pytorch代码,大家只用在原有的pytorch代码中加入两行就可以用我们的模块。
丰富的潜在应用场景

图8 丰富的潜在应用
包括替换transformer,解迷宫问题和视频特征增强
我们相信learnable tree filter还有很多的潜在应用场景,图8给出了三个例子
1)替换transformer中的attention模块;
2)由于我们算法可以建模高阶关系,这可能对因果推断,解迷宫也会有帮助;
3)高效的推断可能会帮助视频分析类任务提取高分辨率的时序信息。

Rethinking Learnable Tree Filter for Generic Feature Transform
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加微信群
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777



