techblog.toutiao.com/2017/06/06/xss/
什么是XSS
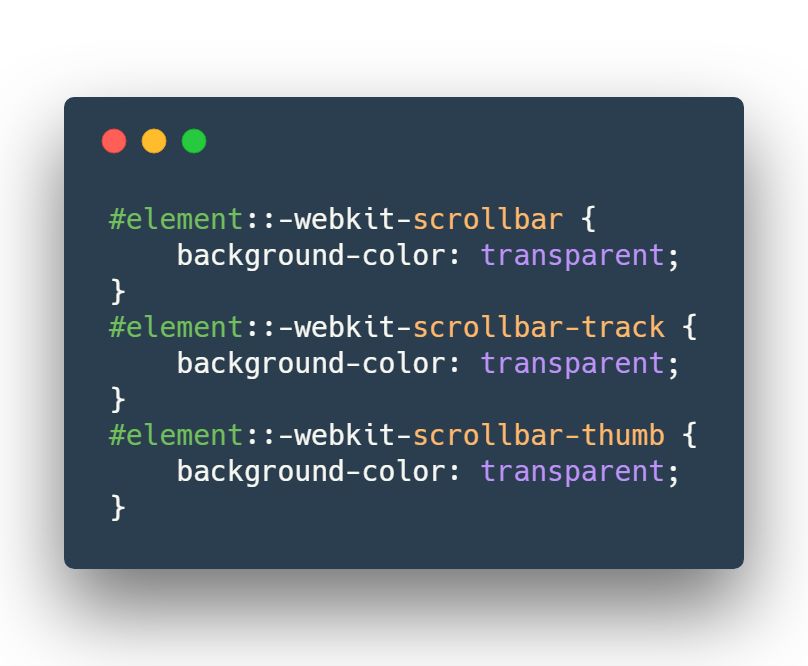
跨站脚本攻击(Cross Site Scripting),为不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。
XSS的攻击场景
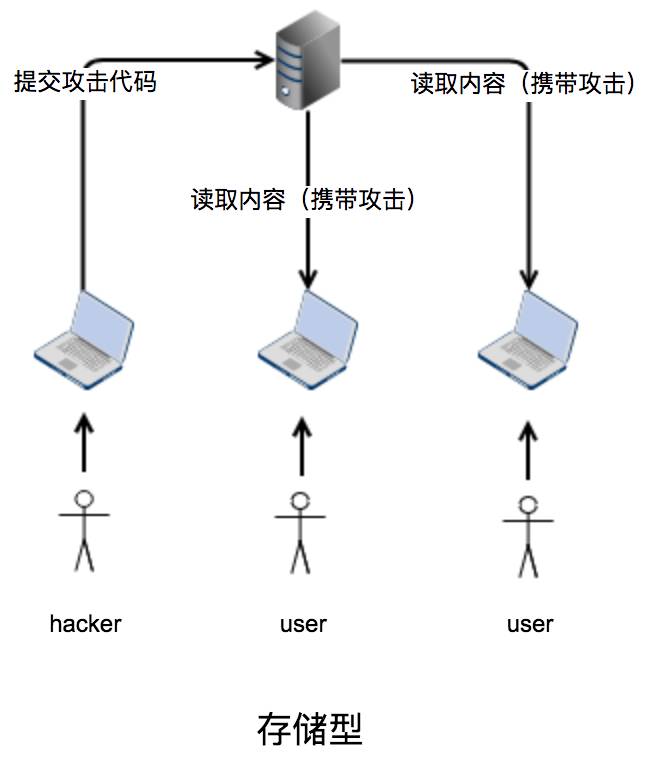
从上下两个流程图来看,反射型和存储型的攻击方式是本质不同的,前者需要借助各种社交渠道传播具备攻击的URL来实施,后者通过网站本身的存储漏洞,攻击成本低很多,而且伤害力更大。
XSS的工作原理
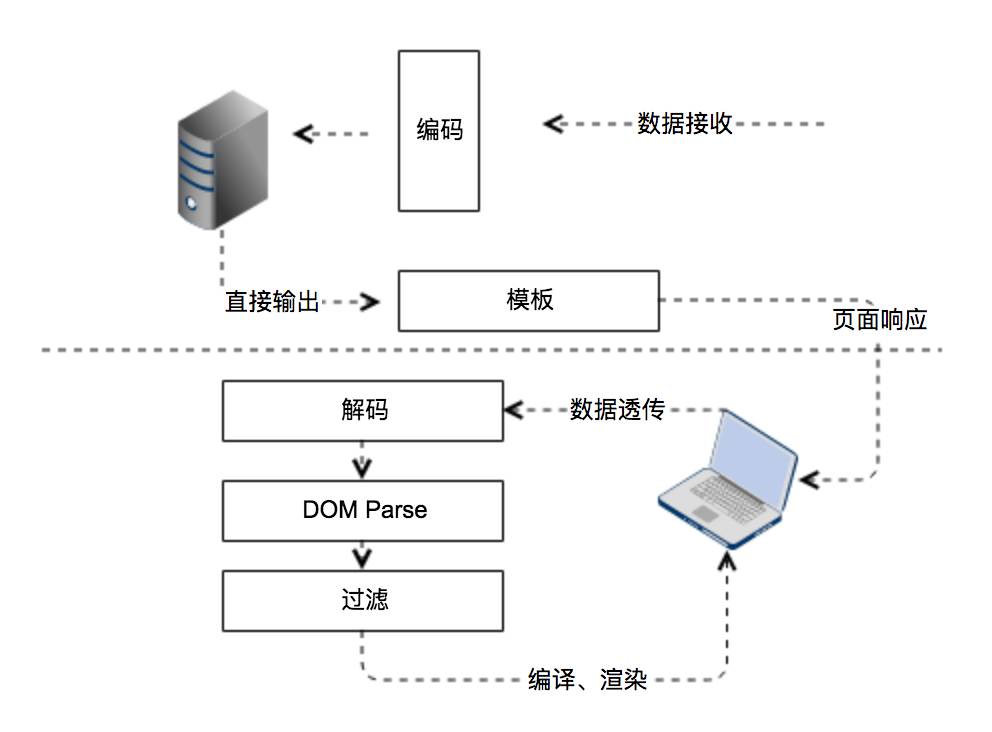
不管是反射型还是存储型,服务端都会将JavaScript当做文本处理,这些文本在服务端被整合进html文档中,在浏览器解析这些文本的过程也就是XSS被执行的时候。
从攻击到执行分为以下几步:
构造攻击代码
服务端提取并写入HTML
浏览器解析,XSS执行
构造攻击代码
hacker在发现站点对应的漏洞之后,基本可以确定是使用“反射型”或者“存储型”。对于反射型这个很简单了,执行类似代码:
大家知道很多站点都提供搜索服务,这里的item字段就是给服务端提供关键词。如果hacker将关键词修改成可执行的JavaScript语句,如果服务端不加处理直接将类似代码回显到页面,XSS代码就会被执行。
这段代码的含义是告诉浏览器加载一张图片,图片的地址是空,根据加载机制空图片的加载会触发Element的onerror事件,这段代码的onerror事件是将本地cookie传到指定的网站。
很明显,hacker可以拿到“中招”用户的cookie,利用这个身份就可以拿到很多隐私信息和做一些不当的行为了。
对于存储型直接通过读取数据库将内容打到接口上就可以了。
服务端提取并写入HTML
我们以 Node.js 应用型框架express.js为例:
服务端代码(express.js)
router.get(‘/’,function(req,res,next){
res.render(‘index’,{
title: ‘Express’,
search: req.query.item
});
});
ejs模板
这里列举了以反射型为主的服务端代码,通过获取URL的查询res.query.item,最后在模板中输出内容。对于存储型的区别是通过数据库拿到对应内容,模板部分一致。
浏览器解析,XSS执行
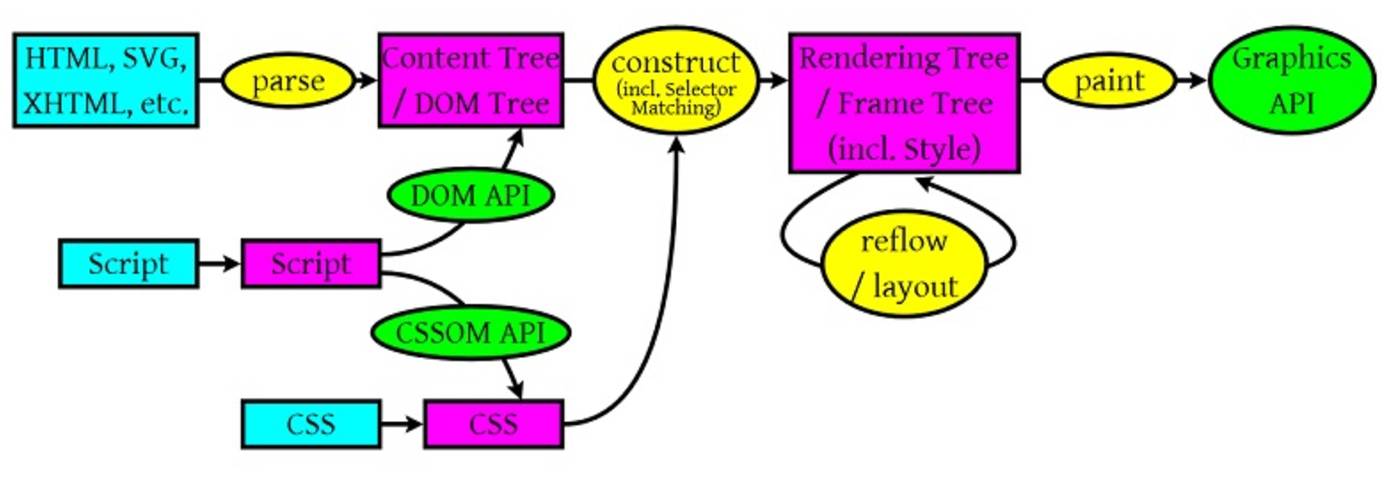
从这个图上来看浏览器解析主要做三件事:
在这个过程,XSS的代码从文本变的可执行。
XSS的防范措施
编码
对于反射型的代码,服务端代码要对查询进行编码,主要目的就是将查询文本化,避免在浏览器解析阶段转换成DOM和CSS规则及JavaScript解析。
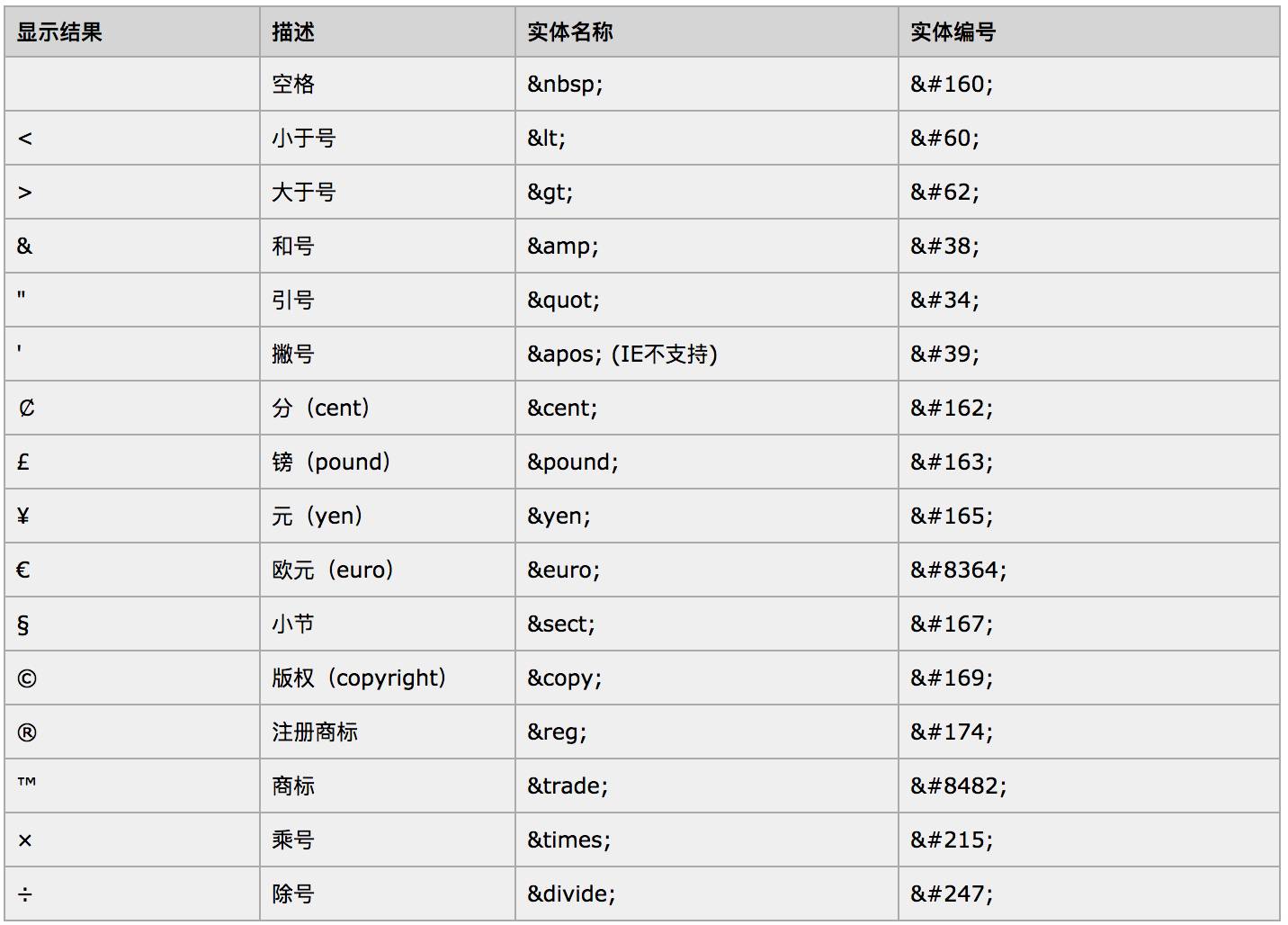
常见的HTML实体编码如下:
除了编码和解码,还需要做额外的共奏来解决富文本内容的XSS攻击。
我们知道很多场景是允许用户输入富文本,而且也需要将富文本还原。这个时候就是hacker容易利用的点进行XSS攻击。
DOM Parse和过滤
从XSS工作的原理可知,在服务端进行编码,在模板解码这个过程对于富文本的内容来说,完全可以被浏览器解析到并执行,进而给了XSS执行的可乘之机。
为了杜绝悲剧发生,我们需要在浏览器解析之后进行解码,得到的文本进行DOM parse拿到DOM Tree,对所有的不安全因素进行过滤,最后将内容交给浏览器,达到避免XSS感染的效果。
具体原理如下:
varunescape = function(html,options){
options = merge(options,decode.options);
varstrict = options.strict;
if(strict && regexInvalidEntity.test(html)){
parseError(‘malformed character reference’);
returnhtml.replace(regexDecode,function($0,$1,$2,$3,$4,$5,$6,$7){
varcodePoint;
varsemicolon;
vardecDigits;
varhexDigits;
varreference;
varnext;
if($1){
// Decode decimal escapes, e.g. “.
decDigits = $1;
semicolon = $2;
if(strict && !semicolon){
parseError(‘character reference was not terminated by a semicolon’);
codePoint = parseInt(decDigits,10);
returncodePointToSymbol(codePoint,strict);
if($3){
// Decode hexadecimal escapes, e.g. “.
hexDigits = $3;
semicolon = $4;
if(strict && !semicolon){
parseError(‘character reference was not terminated by a semicolon’);
codePoint = parseInt(hexDigits,16);
returncodePointToSymbol(codePoint,strict);
if($5){
// Decode named character references with trailing `;`, e.g. `©`.
reference = $5;
if(has(decodeMap,reference)){
returndecodeMap[reference];
}else{
// Ambiguous ampersand.
if(strict){
parseError(
‘named character reference was not terminated by a semicolon’
);
return$0;
// If we’re still here, it’s a legacy reference for sure. No need for an
// extra `if` check.
// Decode named character references without trailing `;`, e.g. `&`
// This is only a parse error if it gets converted to `&`, or if it is
// followed by `=` in an attribute context.
reference = $6;
next = $7;
if(next && options.isAttributeValue){
if(strict && next == ‘=’){
parseError(‘`&` did not start a character reference’);
return$0;
}else{
if(strict){
parseError(
‘named character reference was not terminated by a semicolon’
);
// Note: there is no need to check `has(decodeMapLegacy, reference)`.
returndecodeMapLegacy[reference] + (next || ”);
});
};
varparse=function(str){
varresults=”;
try{
HTMLParser(str,{
start:function(tag,attrs,unary){
if(tag==’script’ || tag==’style’|| tag==’img’|| tag==’link’){
return
results+=””;
},
end:function(tag){
results+=””+tag+”>”;
},
chars:function(text){
results+=text;
},
comment:function(){
results+=”‘;
})
returnresults;
}catch(e){
}finally{
};
vardst=parse(str);
在此展示了部分代码,其中DOM Parse可以采用第三方的Js库来完成。
XSS的危害
相信大家都对XSS了有一定的了解,下面列举几个XSS影响比较大的事件供参考,做到警钟长鸣。
如果本文有描述不准确或错误,欢迎大家指正……,不胜感激。
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,一年会员只需98元,全站资源免费下载 点击查看详情
站 长 微 信: lzxmw777